Microservices vs Monolith Architecture
An honest comparison of microservices and monolithic architecture, including when each is the right choice, the hidden costs of microservices, and how the modular monolith offers a practical middle ground.
What a monolith is and why it deserves more respect
A monolithic architecture deploys an entire application as a single unit. One codebase, one build artifact, one deployment pipeline, one process at runtime. The microservices vs monolith debate often frames monoliths as outdated, but that framing ignores the engineering reality: monoliths are simpler to develop, test, deploy, and debug than distributed systems. Every function call within a monolith is a local call with nanosecond latency. In a microservices architecture, the equivalent interaction is a network call with millisecond latency, failure modes, serialization overhead, and the need for retry logic and circuit breakers. A single-process monolith has one deployment. Roll it back and the entire application returns to the previous version. Monoliths share a single database, which means transactions are ACID-compliant without coordination protocols. Transferring money between two accounts in a monolith is a single database transaction. In microservices, it's a distributed saga with compensating transactions, eventual consistency, and partial failure modes that take weeks to implement correctly. Stack Overflow serves 1.3 billion page views per month from a monolithic .NET application running on a handful of servers. Basecamp (37signals) runs a monolithic Ruby on Rails application serving millions of users. Shopify ran as a monolith for over a decade before selectively extracting services. These are not small projects on legacy technology. They are deliberate architectural choices by experienced engineering teams who decided the operational simplicity of a monolith outweighed the theoretical benefits of microservices. The question isn't whether monoliths scale. It's whether your specific scaling challenges require distribution.
What microservices actually cost you in operational complexity
A microservices architecture decomposes an application into independently deployable services, each owning its own data store, communicating over network protocols. The benefits are real: independent deployment, technology choice per service, and the ability to scale individual services based on their specific load patterns. But the costs are frequently underestimated. Distributed tracing becomes mandatory. When a user request traverses 5 services, you need a correlation ID propagated through every HTTP header and log entry to debug latency issues. Without OpenTelemetry or Jaeger, a production incident involving three services and a message queue takes hours to diagnose. With a monolith, you get a stack trace. Service discovery adds a moving part. Services need to find each other. Kubernetes provides DNS-based service discovery, but you're now operating a Kubernetes cluster. Consul provides service mesh capabilities, but that's another distributed system to maintain. Every service needs health checks, and the orchestrator needs to route traffic away from unhealthy instances. Network reliability replaces in-process reliability. In a monolith, a method call either succeeds or throws an exception. In microservices, a network call can succeed, fail, time out, return a partial result, or succeed but deliver the response after the caller has already timed out and retried, causing duplicate processing. You need idempotency keys, retry policies with exponential backoff, and circuit breakers on every inter-service call. Data consistency becomes your problem. Each service owns its database, so there's no cross-service transaction. Placing an order requires the Order Service to write the order, the Inventory Service to reserve stock, and the Payment Service to charge the customer. If payment fails after inventory is reserved, you need a compensating transaction to release the stock. The Saga pattern handles this, but implementing it correctly with failure handling for every step is a multi-week engineering effort per workflow.
When a monolith is the right choice: small teams, early products, simple domains
Start with a monolith if your engineering team has fewer than 10 people. The primary organizational benefit of microservices is enabling independent teams to deploy without coordinating with each other. A 6-person team doesn't have that coordination problem. They sit in the same room (or Slack channel), they review each other's code, and they can deploy the entire application in one pipeline. Splitting into microservices adds operational overhead with no organizational benefit. Start with a monolith if your product is in the first two years of development. Early-stage products change direction frequently. Feature boundaries shift. What seems like a clean service boundary today becomes a cross-cutting concern next quarter. In a monolith, refactoring across module boundaries is a code change. In microservices, refactoring across service boundaries requires changing APIs, updating contracts, migrating data between databases, and coordinating deployments. Instagram ran as a Django monolith through its acquisition by Facebook with 30 million users. The speed of iteration in a monolith is hard to match with microservices. Start with a monolith if your domain is simple. A CRUD application with a few dozen entities, straightforward business rules, and no need for independent scaling doesn't benefit from distribution. An internal tool for managing employee timesheets doesn't need an API gateway, service mesh, and distributed tracing. It needs a Rails app with a PostgreSQL database. Engineering effort spent on microservices infrastructure is effort not spent on solving the actual business problem. The time to consider microservices is when you have a specific, measurable problem that a monolith can't solve: one component needs to scale to 10x the load of others, two teams are constantly blocked by each other's deployments, or a component needs a technology stack incompatible with the monolith's runtime.
When microservices solve real problems: scaling, autonomy, tech flexibility
Microservices are justified when independent scaling is a measurable requirement, not a theoretical concern. Netflix processes billions of API requests daily, but their video encoding service has fundamentally different scaling characteristics than their recommendation engine. Video encoding is CPU-bound and bursty (when new content launches). Recommendations are memory-bound and steady-state. Running both in a monolith means over-provisioning CPU for recommendations or under-provisioning for encoding. Separate services scale to their actual resource profiles. Team autonomy becomes a real problem when an organization grows beyond 50 engineers. Amazon's 'two-pizza team' rule (teams small enough to be fed by two pizzas) emerged because coordination overhead grows quadratically with team size. When 8 teams share a monolith, every deployment requires integration testing across all teams' changes. Merge conflicts become daily occurrences. Release trains slow deployments to weekly or biweekly cycles. Microservices let each team own their service, deploy on their own schedule, and maintain their own quality gates. Technology flexibility matters when specific services have specific technical requirements. A machine learning inference service might need Python with PyTorch. A low-latency trading system might need Rust or C++. A data processing pipeline might need Scala with Apache Spark. In a monolith, you're constrained to one technology stack. Microservices let each service choose the runtime that fits its workload. Spotify uses this approach: their backend services run on Java and Python depending on the team and use case, connected through well-defined gRPC interfaces. Fault isolation is the fourth valid reason. A memory leak in one service crashes that service, not the entire application. A spike in traffic to the search service doesn't affect the checkout flow. This isolation requires proper bulkheading: separate thread pools, separate database connections, and separate infrastructure for critical services.
The modular monolith: getting 80% of the benefits with 20% of the cost
A modular monolith deploys as a single unit but maintains strict internal boundaries between modules. Each module has its own domain model, its own database schema (or at least its own schema within a shared database), and well-defined interfaces for inter-module communication. Modules cannot access each other's internal state directly. They communicate through public APIs: method calls, events, or shared interfaces. Shopify moved to a modular monolith architecture they call 'componentized monolith.' They enforce module boundaries using a custom Ruby gem that prevents one module from requiring files in another module's internal directory. Each component owns its database tables. Inter-component communication happens through well-defined Ruby interfaces. This gives them the organizational benefits of clear ownership boundaries while maintaining the operational simplicity of a single deployment. The key discipline in a modular monolith is enforcing boundaries. Without enforcement, boundaries erode. A developer in module A finds it faster to directly query module B's database table than to use the public interface. Six months later, modules A and B are so entangled that splitting them into separate services would require rewriting both. Tools like ArchUnit (Java), Packwerk (Ruby), and custom lint rules enforce that module boundaries are respected in code. If your eventual goal is microservices, a modular monolith is the best starting point. Each module can become a service when the organizational or technical pressure justifies extraction. The module interfaces become service APIs. The internal event bus becomes a message broker. The shared database becomes service-specific databases with data migration. This incremental extraction is far safer than a big-bang rewrite from a tangled monolith to 20 services. Martin Fowler's advice holds: 'Don't even consider microservices unless you have a system that's too complex to manage as a monolith.' Start modular. Extract when you must.
Diagramming monoliths and microservices architectures
The way you diagram a monolith differs fundamentally from how you diagram microservices, and getting the visual representation right is crucial for architectural discussions. A monolith diagram shows the external interfaces and internal module structure. Draw a single large rectangle for the application. Inside it, draw smaller rectangles for each module: Auth, Orders, Inventory, Payments, Notifications. Draw arrows between modules showing internal communication. Outside the monolith boundary, draw the database, cache, file storage, and external services it connects to. The single deployment boundary is the most important visual element. It communicates that everything inside is one process, one deployment, one scaling unit. A microservices diagram shows independent services with network connections. Each service is its own box with its own database drawn below it. The API gateway sits at the entry point, routing requests to the appropriate service. Message brokers (Kafka, SQS, RabbitMQ) sit between services that communicate asynchronously. Draw synchronous calls as solid arrows and asynchronous event flows as dashed arrows. Label every connection with the protocol: REST, gRPC, AMQP, or Kafka topic names. Show the service mesh sidecar proxies if you're using Istio or Linkerd. The visual complexity of a microservices diagram is itself informative. When you draw 15 services with 30 inter-service connections, the diagram screams 'distributed system complexity.' That's honest. If the diagram looks complicated, the system is complicated. Diagrams.so generates both monolithic and microservices architecture diagrams from text descriptions. Describe your system's components and their communication patterns, and get a .drawio file with proper service boundaries, labeled connections, and infrastructure components. The visual distinction between monolith and microservices architectures makes architectural trade-off discussions concrete rather than abstract.
Real-world examples
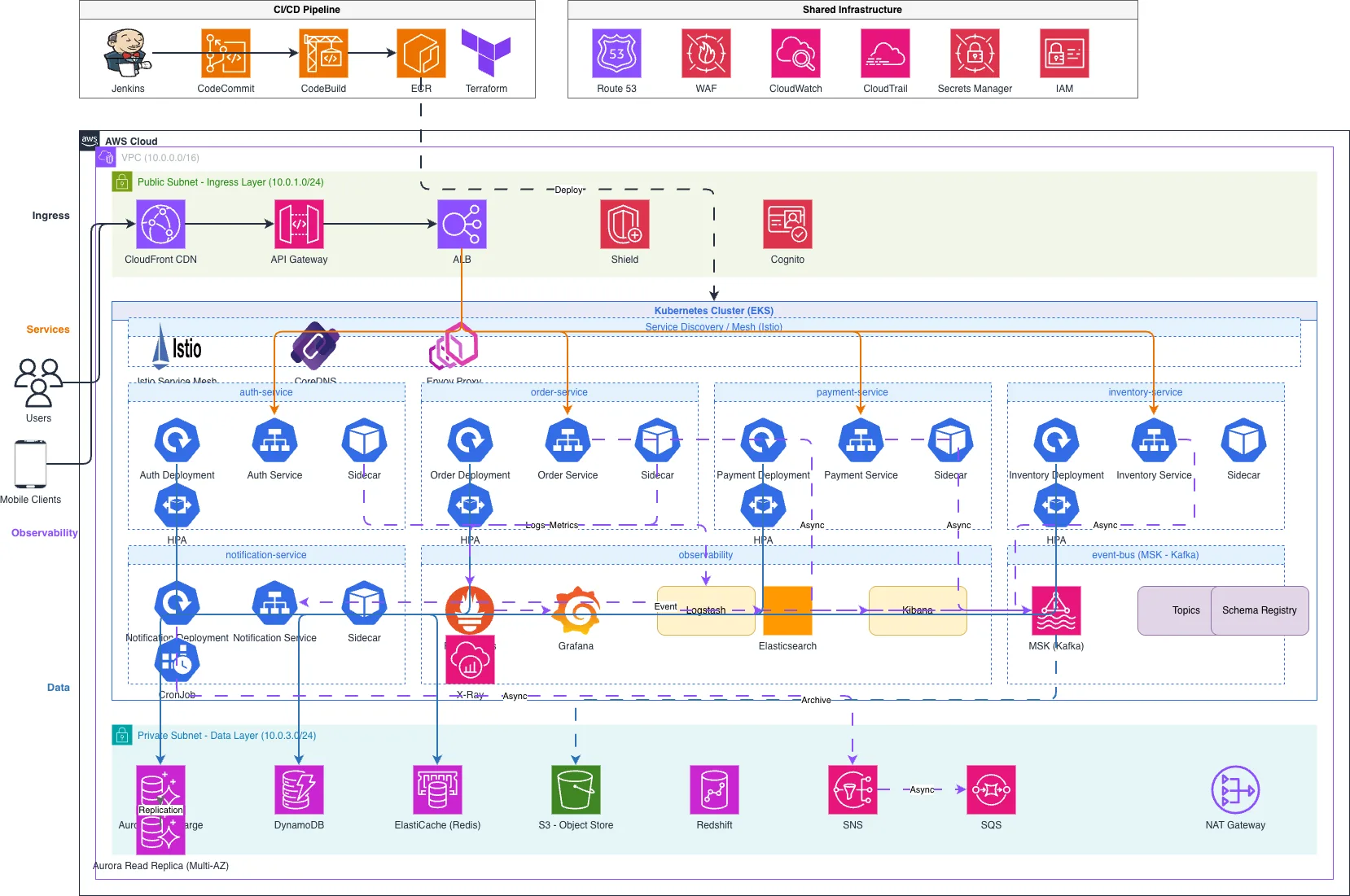
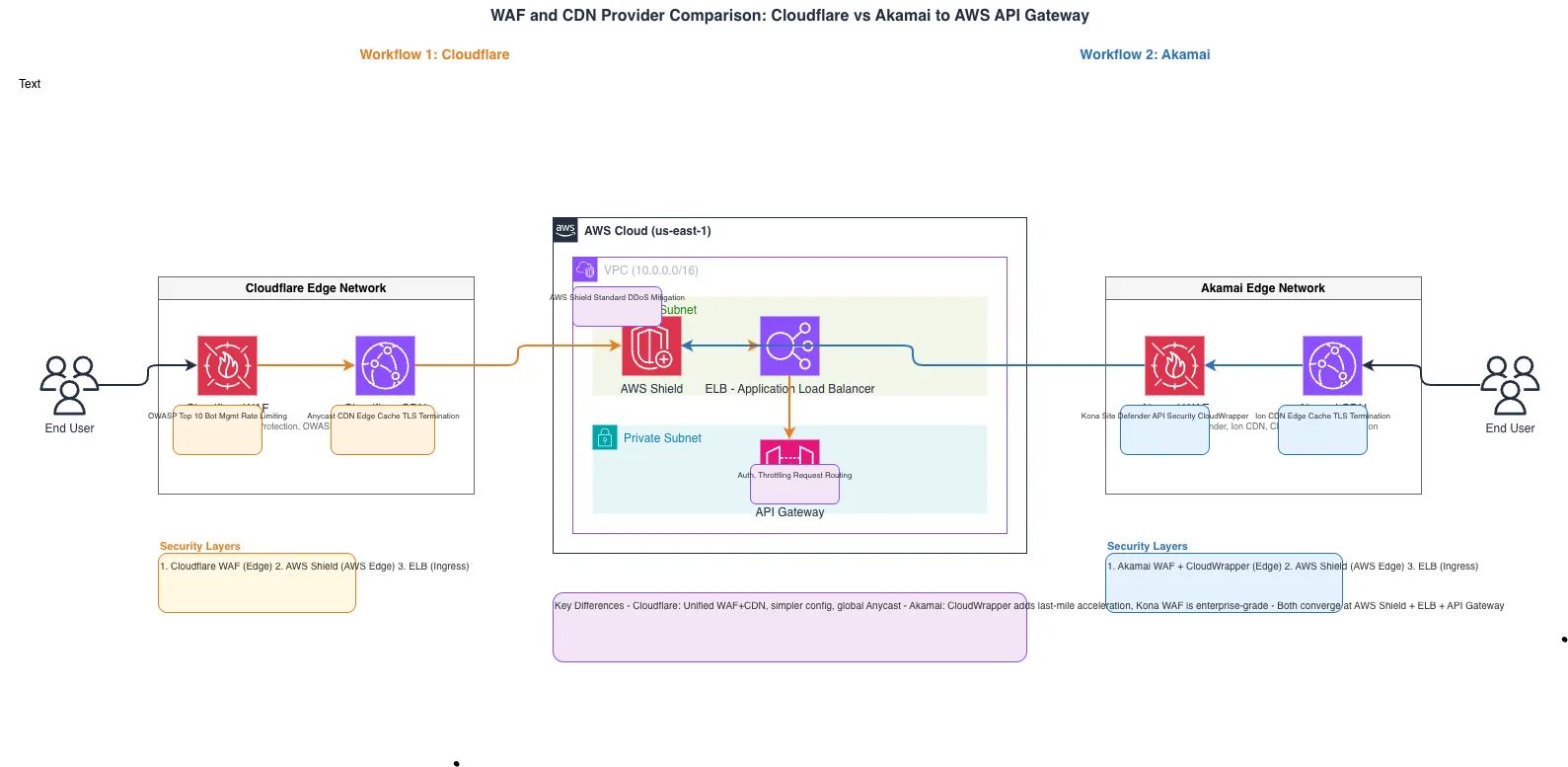
Generate these diagrams with AI
Generate Microservices Architecture Diagrams from Text
Describe your service boundaries in plain English. Get a valid Draw.io diagram with API gateways, message brokers, database-per-service patterns, and service mesh routing.
Generate System Architecture Diagrams from Text
Describe your system's components in plain English. Get a valid Draw.io diagram with services, databases, message queues, caches, and API connections.
Generate API Gateway Diagrams from Text with AI
Describe your API gateway routing, auth, and rate limiting in plain English. Get a valid Draw.io diagram with request flows, middleware chains, and backend services.