What Is an ERD (Entity-Relationship Diagram)?
An ERD maps the tables, columns, and relationships in a database. It is the primary tool for designing relational schemas before writing a single line of SQL.
What an ERD represents and why it exists
An entity-relationship diagram (ERD) is a visual representation of a database schema showing entities (tables), their attributes (columns), and the relationships between them. What is an ERD in day-to-day engineering? It's the diagram you draw before writing CREATE TABLE statements. It forces you to think about data structure, constraints, and access patterns before committing to a schema that's expensive to change once data exists. Peter Chen introduced the ER model in 1976. His original paper described entities as 'things which can be distinctly identified' and relationships as 'associations among entities.' The model has evolved significantly since then, but the core idea remains: separate the logical data structure from the physical storage implementation. ERDs operate at three levels of abstraction. Conceptual ERDs show entities and relationships without attributes. They answer 'what data does the system manage?' for business stakeholders. Logical ERDs add attributes, primary keys, and foreign keys. They answer 'how is the data structured?' for application developers. Physical ERDs include data types, indexes, constraints, and partitioning strategies. They answer 'how is the data stored?' for database administrators. Most teams skip the conceptual level and start at logical. That's fine for small schemas. For a system with 50+ tables, the conceptual view helps stakeholders validate that the data model captures all business entities before engineers invest time in column definitions.
Notation types: Crow's Foot vs Chen vs UML class diagrams
Three notation systems dominate ERD drawing, and you should pick Crow's Foot for any production database design. Skip Chen notation unless you're in an academic setting where your professor requires it. Crow's Foot notation (also called IE notation, after the Information Engineering methodology) uses symbols at the ends of relationship lines to indicate cardinality. A three-pronged fork symbol means 'many.' A single perpendicular line means 'one.' A circle means 'optional' (zero). A perpendicular line means 'mandatory' (at least one). These combine: a circle-and-fork means 'zero or many,' a line-and-fork means 'one or many,' a circle-and-line means 'zero or one.' Crow's Foot is the industry standard because the symbols are visually intuitive. Looking at a line connecting Orders to Customers, the fork on the Orders side immediately communicates 'a customer can have many orders' without reading a label. Chen notation uses diamonds for relationships, ovals for attributes, and rectangles for entities. Relationship cardinality is written as '1' or 'N' beside the connecting lines. Chen diagrams are readable for simple schemas but become unwieldy with complex relationships because every relationship gets its own diamond shape, and attributes hang off entities as individual ovals. A 20-table schema in Chen notation takes four times the canvas space of the same schema in Crow's Foot. UML class diagrams can represent data models using stereotyped classes. Each table becomes a class with a <<table>> stereotype, columns are attributes, and associations carry multiplicity labels like '1..*' or '0..1'. UML is useful when your team already uses it for software design, but it lacks the visual clarity of Crow's Foot for specifically communicating database schemas. The multiplicity numbers are small and easily overlooked.
Cardinality and relationship types: 1:1, 1:N, and M:N with junction tables
Cardinality defines how many instances of one entity relate to instances of another. Getting cardinality wrong leads to schemas that either can't represent real data or contain redundant data that drifts out of sync. One-to-one (1:1) relationships mean each row in table A corresponds to exactly one row in table B. User and UserProfile is a classic example. The profile table has a user_id column with a unique constraint. 1:1 relationships often exist for performance reasons: splitting a wide table so that frequently accessed columns are in one table and rarely accessed BLOB or JSON columns are in another. PostgreSQL's TOAST mechanism handles this automatically for large values, but explicit splits give you control over query patterns. One-to-many (1:N) is the most common relationship type. A Customer has many Orders. A Department has many Employees. An Author has many Articles. The foreign key lives on the 'many' side: orders.customer_id references customers.id. Always index the foreign key column. Without an index, deleting a customer requires a sequential scan of the orders table to check for dependent rows, which becomes catastrophic at scale. Many-to-many (M:N) relationships require a junction table (also called a join table, bridge table, or associative entity). Students enroll in Courses. The enrollment table has student_id and course_id as a composite primary key, plus any attributes of the relationship itself, like enrollment_date and grade. Don't model M:N relationships without a junction table. Some ORMs let you declare M:N with a hidden join table. Make it explicit. The junction table almost always acquires its own attributes over time: timestamps, status flags, metadata. Shopify's product-tag relationship uses a junction table with a sort_order column that controls display sequence.
Normalization and ERD: first through third normal form with examples
Normalization is the process of organizing a schema to reduce data redundancy and prevent update anomalies. ERDs make normalization visible because you can see redundant attributes and missing relationships directly in the diagram. First Normal Form (1NF) requires that every column contains atomic values. No arrays, no comma-separated lists, no nested records. A column 'phone_numbers' containing '555-0100,555-0101' violates 1NF. Split it into a separate PhoneNumber entity with a foreign key back to the person. PostgreSQL supports array columns and JSONB, but using them to avoid creating related tables leads to schemas that can't enforce referential integrity. Store structured, queryable data in normalized tables. Use JSONB for truly unstructured metadata. Second Normal Form (2NF) requires that every non-key attribute depends on the entire primary key, not just part of it. This matters for tables with composite primary keys. In an OrderItems table with a composite key of (order_id, product_id), a column 'product_name' depends only on product_id, not on the full composite key. Move product_name to the Products table. The symptom of a 2NF violation is the same product name appearing in thousands of order item rows, requiring bulk updates when a product is renamed. Third Normal Form (3NF) requires that no non-key attribute depends on another non-key attribute (no transitive dependencies). An Employee table with columns department_id, department_name, and department_location has a transitive dependency: department_name depends on department_id, not on the employee's primary key. Extract department_name and department_location into a Department table. Bill Kent summarized the first three normal forms: 'Every non-key attribute must provide a fact about the key, the whole key, and nothing but the key.' Most production databases target 3NF for transactional tables and selectively denormalize for read-heavy analytics tables.
Best practices: naming, typing, and marking keys
Use singular table names. A table called 'users' is a collection of user rows, but the entity it represents is 'User.' Singular names read better in relationships: 'an Order belongs to a Customer' versus 'an Orders belongs to a Customers.' Rails popularized plural table names, and that convention persists in many ORMs, but singular is clearer in ERDs and SQL queries. Consistency matters more than which convention you choose, so pick one and enforce it across the entire schema. Name primary keys 'id' and foreign keys '{referenced_table}_id'. An orders table has 'id' as its primary key and 'customer_id' as the foreign key to customers. This convention is self-documenting. When you see customer_id in a query, you instantly know it references the customers table. Avoid ambiguous names like 'parent_id' unless the self-referential relationship is obvious from context (like a categories table with a tree structure). Include data types on physical ERDs. Knowing that a column is a UUID versus a BIGINT versus a VARCHAR(255) affects query performance, storage size, and application code. PostgreSQL's UUID type is 16 bytes. A BIGINT is 8 bytes. For high-volume tables with billions of rows, that difference matters. Mark primary keys with 'PK' and foreign keys with 'FK' visually in the diagram. Many ERD tools use key icons. At minimum, bold the PK column name. Add 'NOT NULL' annotations on required columns and 'UNIQUE' on natural keys. Add created_at and updated_at timestamps to every table. These cost almost nothing in storage but provide essential debugging information. When a customer reports a data issue, the first question is always 'when was this record last modified?' Index foreign key columns and any column used in WHERE clauses or JOIN conditions.
Generating ERDs from text descriptions or SQL DDL
Traditional ERD tools require dragging entity boxes, adding columns one by one, and drawing relationship lines manually. For a schema with 15 tables and 40 relationships, this takes an hour of tedious layout work. Two faster approaches exist: generating from SQL DDL and generating from natural language. Generating from SQL DDL is deterministic. A CREATE TABLE statement contains everything needed: table name, column names, data types, constraints, primary keys, and foreign key references. Tools parse the DDL and produce an ERD automatically. The challenge is layout. Auto-generated layouts often produce crossing lines and overlapping tables that require manual cleanup. The best tools use force-directed graph algorithms to minimize crossings, but results vary. Natural language generation is more flexible. Describe the domain: 'An e-commerce system with customers, orders, order items, products, categories, and reviews. A customer has many orders. An order has many order items. An order item references one product. A product belongs to one category. A product has many reviews. A review belongs to one customer.' The AI infers entities, attributes, cardinality, and primary/foreign keys from the description. This works well for initial schema design during brainstorming sessions. Diagrams.so generates ERDs from text descriptions and outputs native .drawio files with Crow's Foot notation. Describe your entities, their key attributes, and the relationships between them. The AI produces a grid-aligned ERD with properly marked primary keys, foreign keys, data types, and cardinality symbols. The output opens in Draw.io, where you can refine column details, add indexes, or adjust the layout before exporting to PNG, SVG, or keeping the .drawio file for version control alongside your migration scripts.
Real-world examples
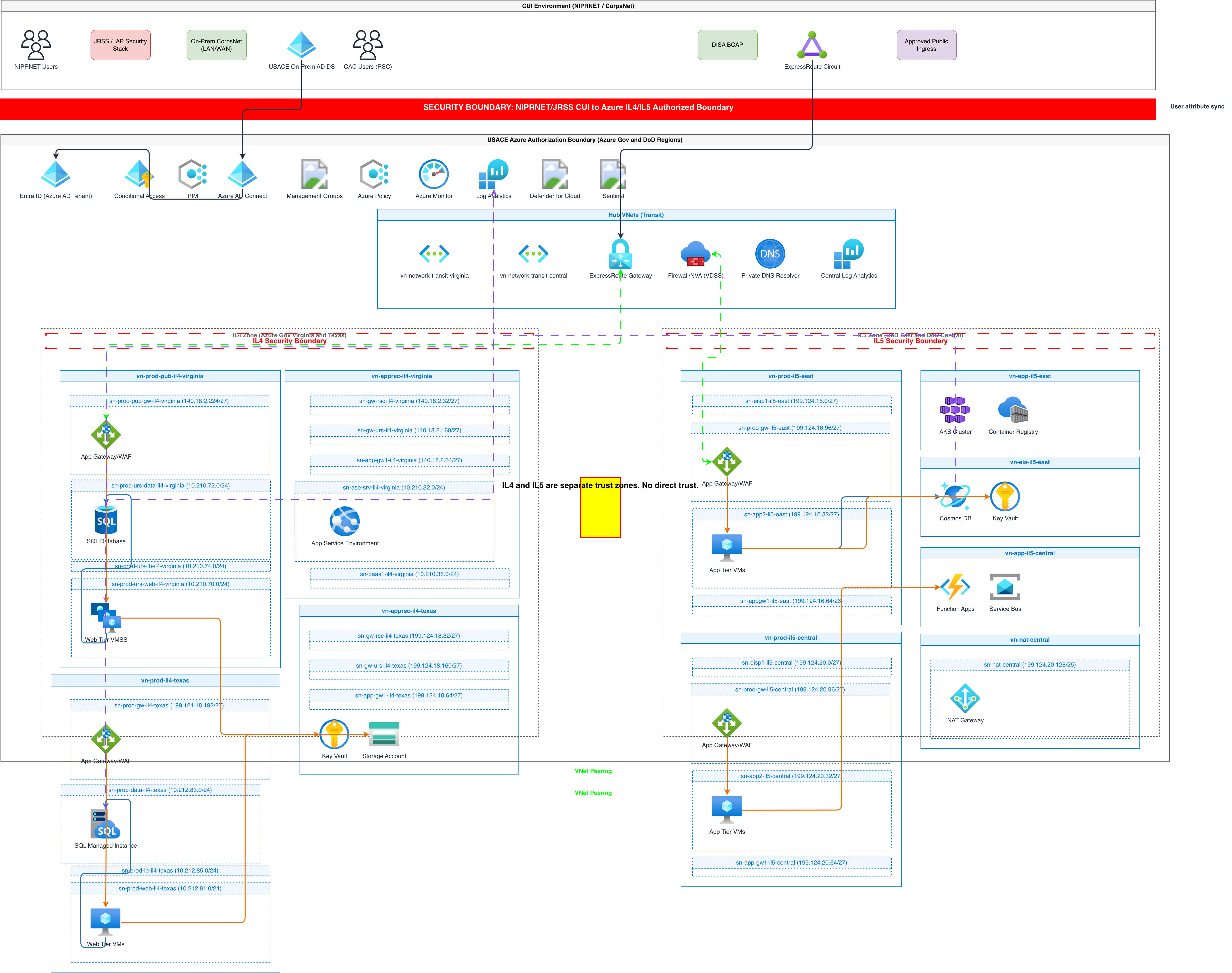

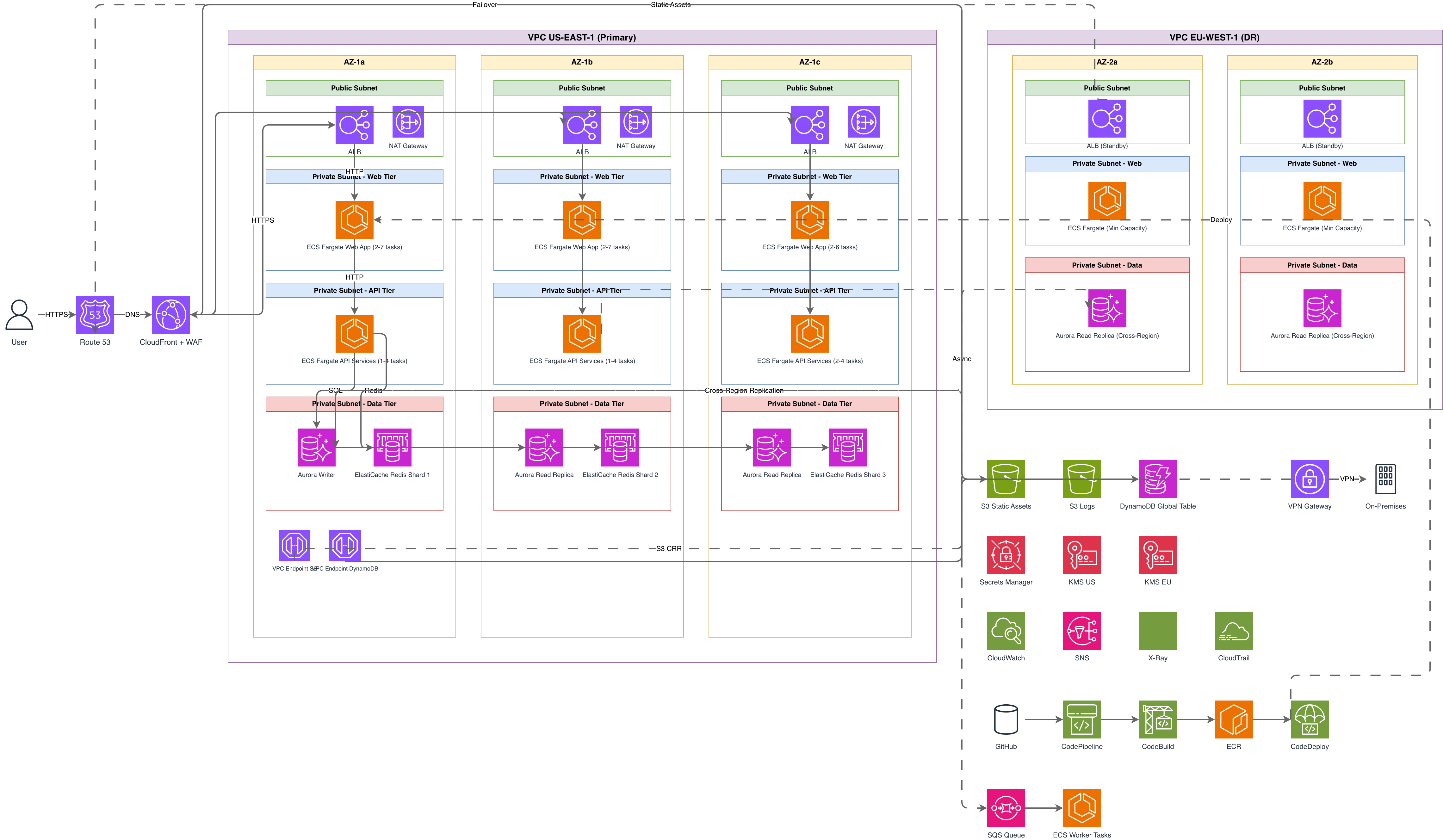
Generate these diagrams with AI
Generate Entity-Relationship Diagrams from Text with AI
Describe your database schema in plain English. Get a valid Draw.io ERD with Crow's Foot notation, cardinality markers, and primary/foreign key labels.
Generate UML Diagrams from Text with AI
Describe your classes, components, or deployment topology in plain English. Get a valid Draw.io UML diagram with correct UML 2.5 notation and relationships.
Generate Data Flow Diagrams from Text with AI
Describe how data moves through your system. Get a valid Draw.io DFD with Yourdon-DeMarco notation, decomposition levels, and named data flows.