Text Tokenization and Embedding Pipeline
About This Architecture
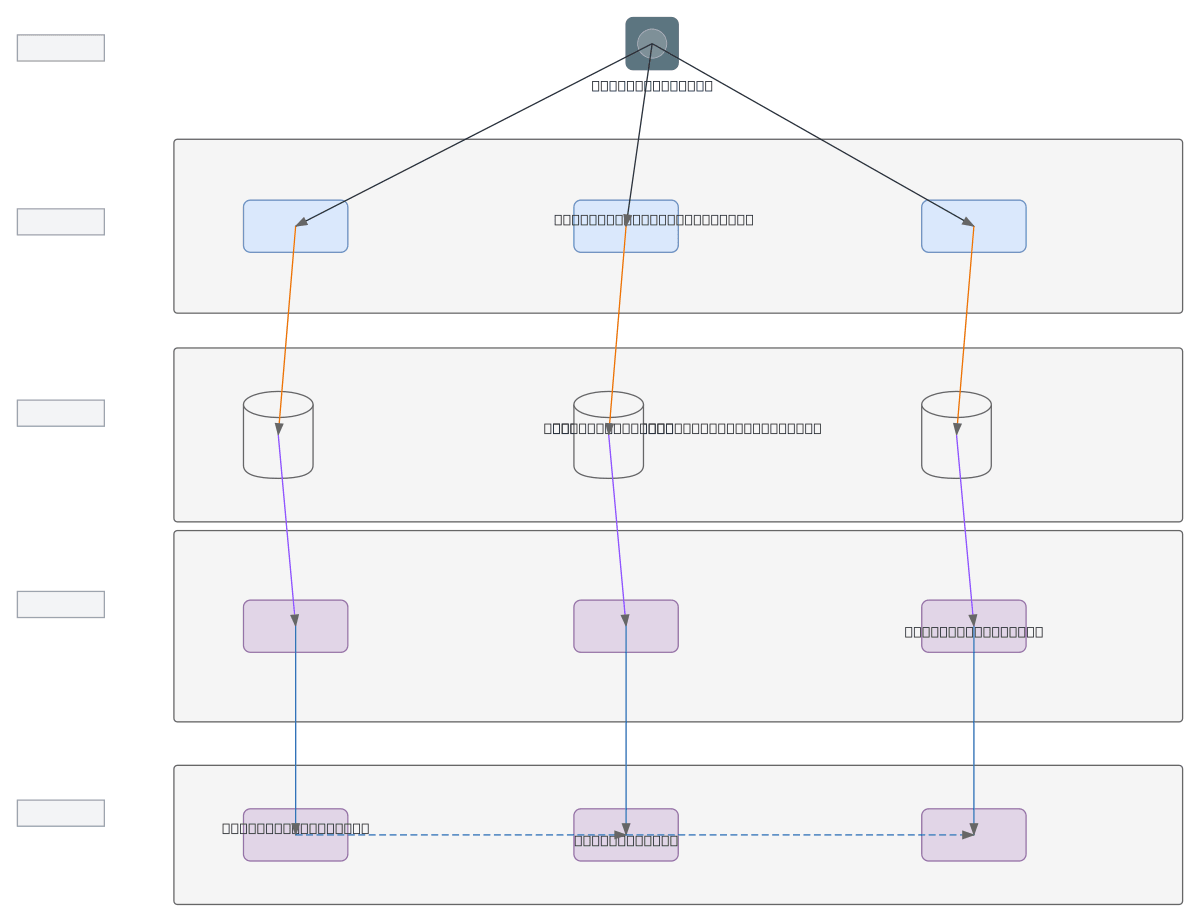
Text tokenization and embedding pipeline on OCI transforms raw text into dense vector representations using character-level, word-level, and subword tokenization strategies. Raw text flows through parallel tokenization layers—character-level, word-level, and BPE subword tokenization—each mapping to dedicated vocabularies before converging into Word2Vec embedding techniques (Skip-gram and CBOW). The pipeline produces character vectors, word vectors, and dense embedding vectors suitable for downstream NLP tasks like classification, similarity search, and language modeling. This architecture demonstrates best practices for scalable text preprocessing and embedding generation on OCI infrastructure. Fork this diagram to customize tokenization strategies, swap embedding models, or integrate with OCI Data Science and Machine Learning services.
People also ask
How do you build a scalable text tokenization and embedding pipeline on OCI for NLP applications?
This diagram shows a parallel tokenization architecture where raw text branches into character-level, word-level, and subword (BPE) tokenization, each feeding dedicated vocabularies. These converge through Word2Vec Skip-gram and CBOW techniques to produce dense embedding vectors suitable for NLP tasks on OCI infrastructure.
- Domain:
- Ml Pipeline
- Audience:
- Machine learning engineers building NLP pipelines on OCI
Generated by Diagrams.so — AI architecture diagram generator with native Draw.io output. Fork this diagram, remix it, or download as .drawio, PNG, or SVG.