M2P End-to-End Data Pipeline Architecture
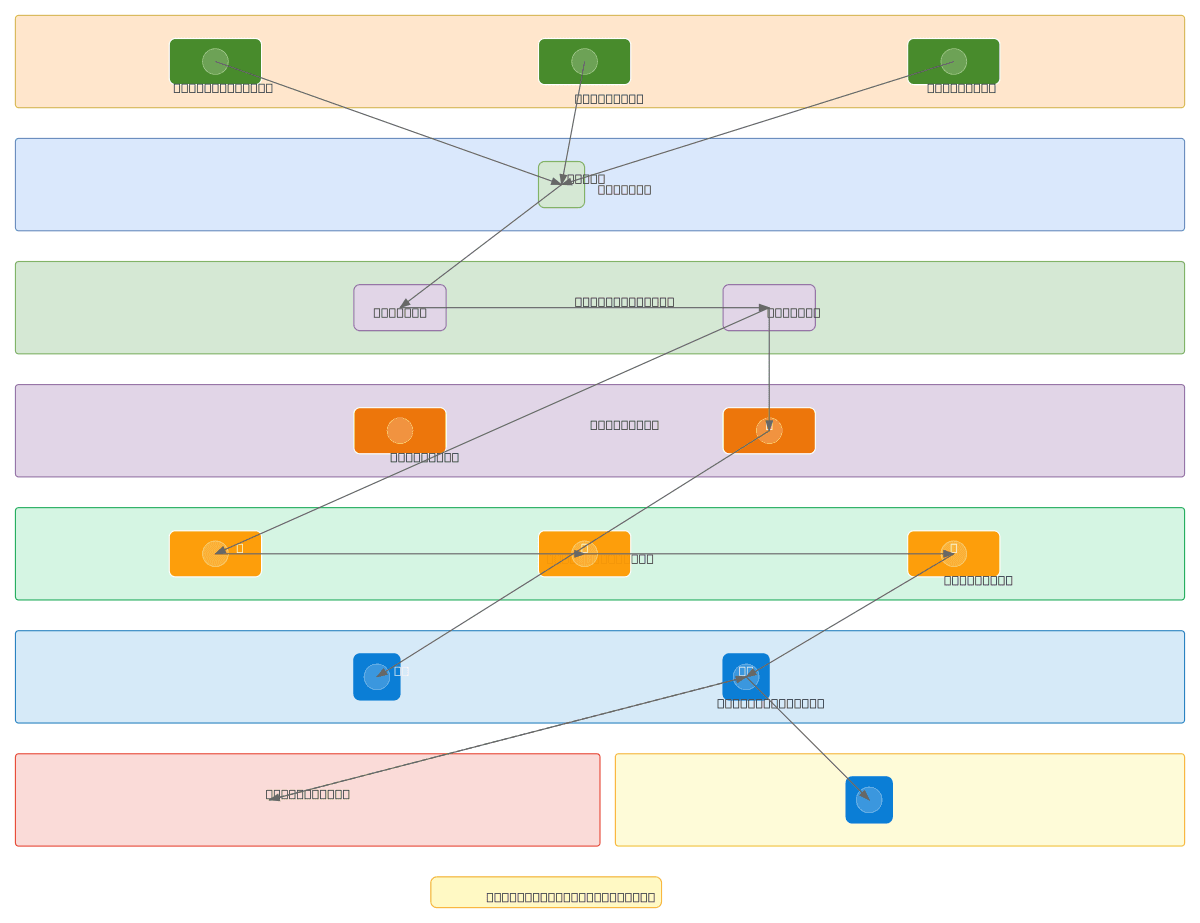
About This Architecture
M2P end-to-end data pipeline orchestrates ingestion from three benchmark sources (16 sheets, MAC, PLOC) into MinIO S3 storage, triggered via Flask webhook to Apache Airflow DAG m2p_pipeline. Sixteen Python loaders normalize and upsert raw data into PostgreSQL staging schema, while dbt transforms 28 staging views through 14 dimensions into 24 fact tables using Kimball constellation modeling. The pipeline feeds both a Prophet-XGBoost ML forecasting model and Power BI analytics dashboard with 225 DAX measures across 8 pages, completing end-to-end in 15-20 minutes. This architecture demonstrates production-grade data orchestration combining batch ingestion, dimensional modeling, machine learning, and self-service BI on AWS infrastructure. Fork and customize this diagram to adapt the pipeline topology, add additional data sources, or modify transformation logic for your own analytics platform.
People also ask
How do you build a complete end-to-end data pipeline with Apache Airflow, dbt, and PostgreSQL that feeds both machine learning and BI dashboards?
The M2P pipeline demonstrates this by ingesting data from three sources into MinIO S3, triggering an Airflow DAG via Flask webhook that orchestrates 16 Python loaders for staging normalization and dbt transformations through 28 views, 14 dimensions, and 24 fact tables in a Kimball constellation. The resulting PostgreSQL DW schema feeds both a Prophet-XGBoost ML model and Power BI dashboard with 22
- Domain:
- Data Engineering
- Audience:
- Data engineers building end-to-end ETL pipelines with Apache Airflow and dbt on AWS
Generated by Diagrams.so — AI architecture diagram generator with native Draw.io output. Fork this diagram, remix it, or download as .drawio, PNG, or SVG.