AWS PROD and AI Account Microservices Architecture
About This Architecture
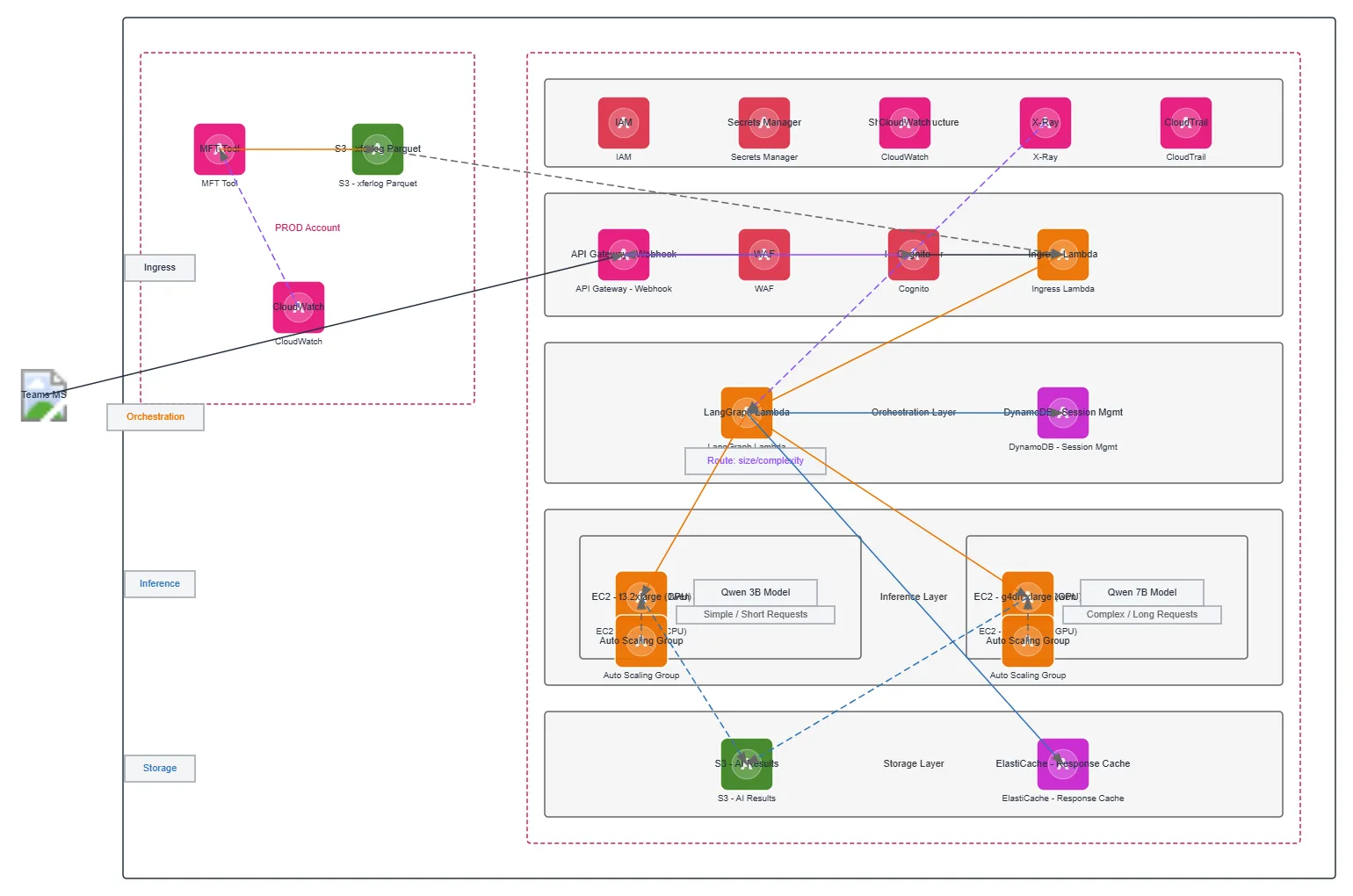
Multi-account AWS microservices architecture routing inference requests across CPU and GPU compute tiers using LangGraph orchestration and Qwen models. Teams MS sends webhook requests through API Gateway and WAF, authenticated via Cognito, then routed by LangGraph Lambda to either t3.2xlarge CPU instances for simple requests or g4dn.xlarge GPU instances for complex workloads. Session state persists in DynamoDB, inference results cache in ElastiCache, and observability spans CloudWatch, X-Ray, and CloudTrail across PROD and AI accounts. This pattern demonstrates cost-optimized inference scaling, least-privilege cross-account IAM, and request-complexity-driven routing for production AI workloads. Fork and customize this diagram on Diagrams.so to adapt compute tiers, add additional inference models, or integrate your own orchestration logic.
People also ask
How do you design a production AWS architecture for AI inference that routes requests to CPU or GPU compute based on complexity?
This diagram shows a multi-account AWS pattern using LangGraph Lambda to intelligently route requests: simple queries to t3.2xlarge CPU instances running Qwen 3B, complex queries to g4dn.xlarge GPU instances running Qwen 7B. DynamoDB maintains session state, ElastiCache caches responses, and cross-account IAM with Secrets Manager enforces least-privilege access.
- Domain:
- Cloud Aws
- Audience:
- AWS solutions architects designing multi-account AI microservices
Generated by Diagrams.so — AI architecture diagram generator with native Draw.io output. Fork this diagram, remix it, or download as .drawio, PNG, or SVG.