AWS Data Lakehouse Architecture - IR-DATAVERSE-DEV
About This Architecture
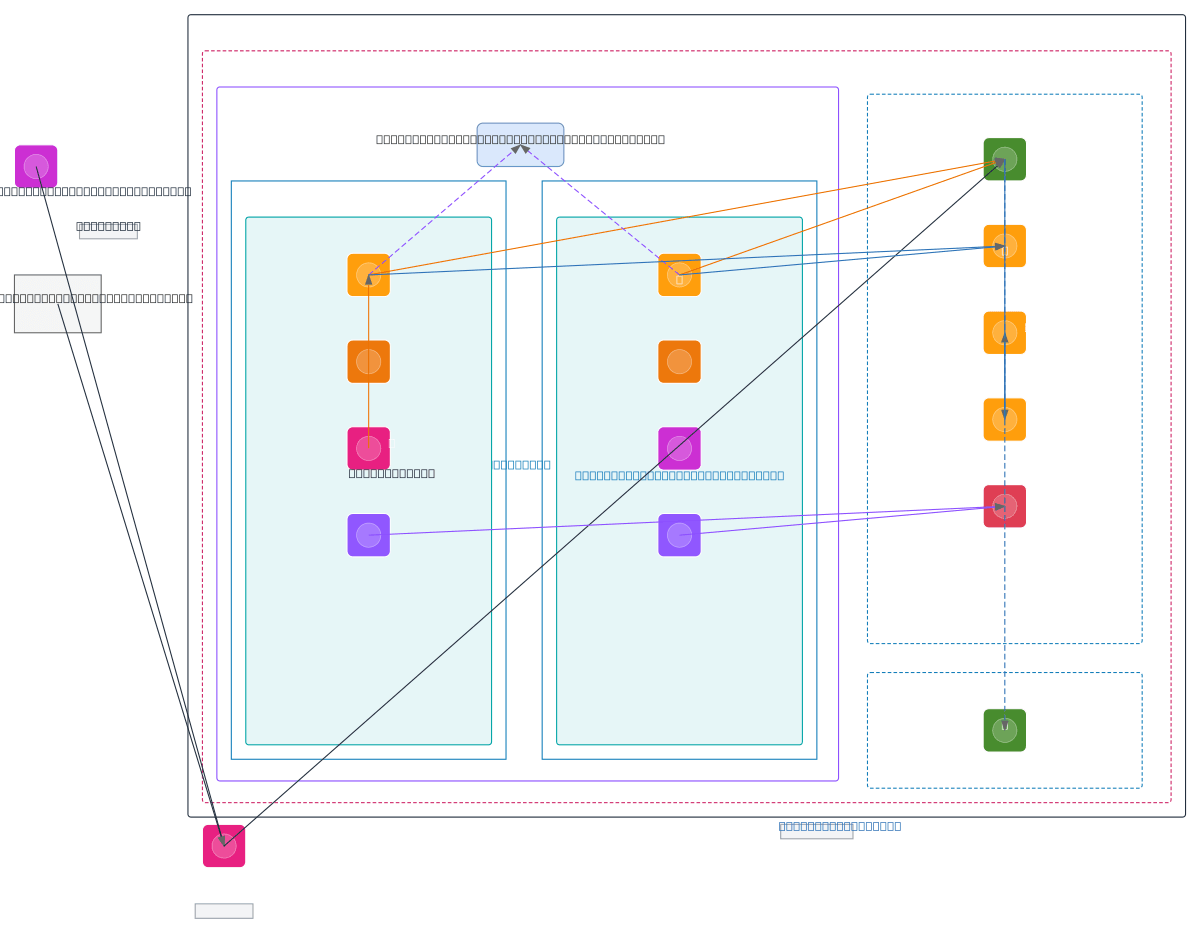
Enterprise data lakehouse combining AWS S3 Iceberg, EMR Spark ETL, and legacy Cloudera CDP for unified analytics across internal (SAP, Veeva, Fieldglass) and external sources (CT.gov, CROs). Data flows from SFTP, MSK Kafka, and API ingestion into zoned S3 data lake, processed by auto-scaling EMR clusters (3–20 nodes) orchestrated via MWAA Airflow across multi-AZ VPC with Redshift Serverless and ECS Fargate. AWS Glue Data Catalog and Lake Formation provide metadata governance while Athena enables SQL analytics, with KMS encryption and CloudWatch monitoring securing the pipeline. Fork this diagram to customize ingestion sources, adjust EMR scaling policies, or extend to additional AWS regions using S3 Cross-Region Replication. The architecture demonstrates hybrid cloud data integration patterns suitable for regulated industries managing complex data lineage and compliance requirements.
People also ask
How do I design a scalable AWS data lakehouse with EMR Spark, Kafka ingestion, and Glue Data Catalog governance?
This diagram shows a production data lakehouse using EMR Spark clusters (auto-scaling 3–20 nodes) to process data from SFTP, MSK Kafka, and APIs into S3 Iceberg zones, with MWAA Airflow orchestration, Glue Data Catalog metadata, and Lake Formation governance. Multi-AZ deployment across us-east-1 with DR replication to us-west-2 ensures high availability and compliance.
- Domain:
- Data Engineering
- Audience:
- Data engineers building enterprise data lakehouses on AWS with multi-source ingestion and hybrid storage
Generated by Diagrams.so — AI architecture diagram generator with native Draw.io output. Fork this diagram, remix it, or download as .drawio, PNG, or SVG.