MLOps Heart Disease - ML Pipeline Completo
About This Architecture
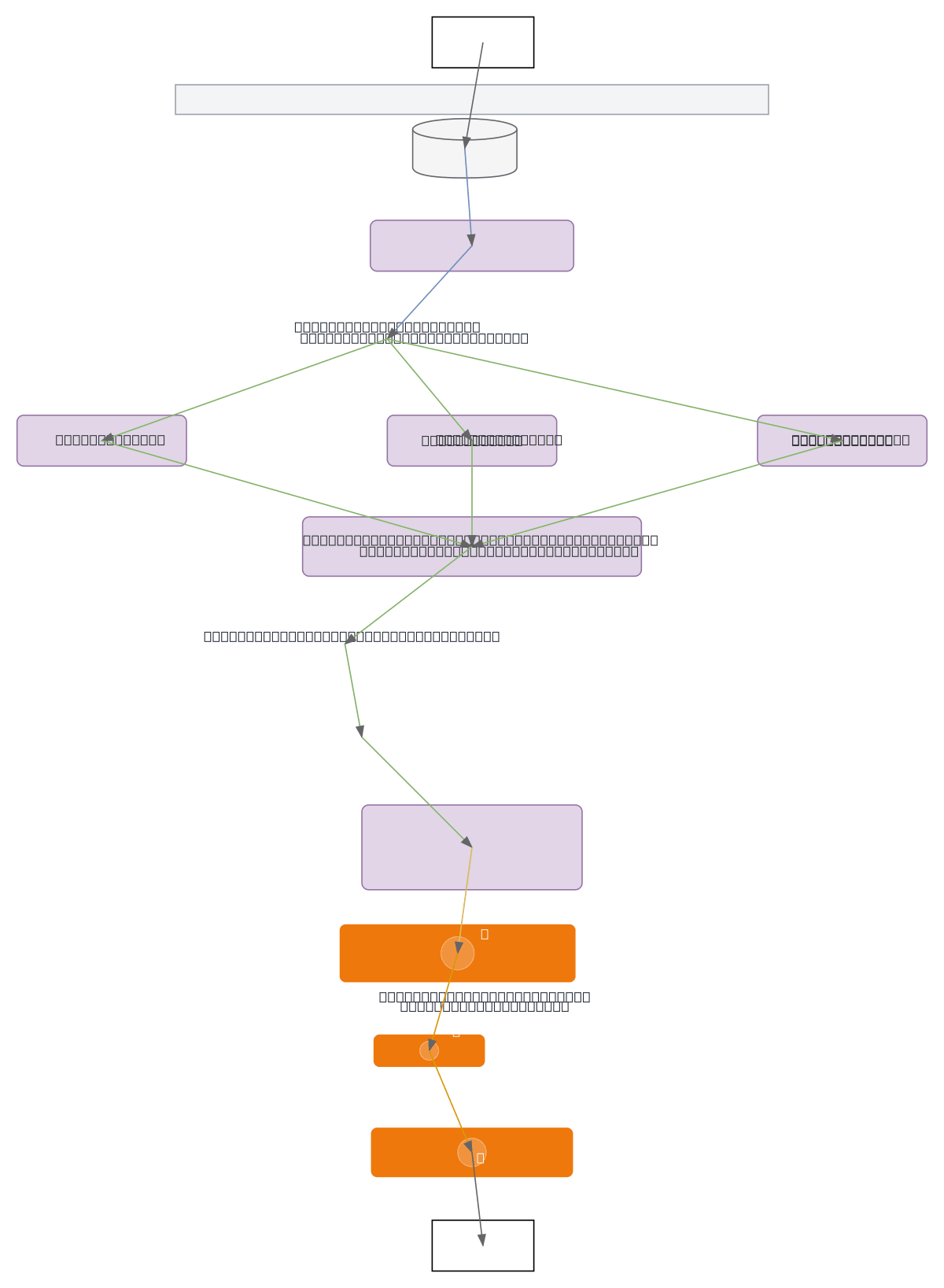
End-to-end MLOps pipeline for heart disease prediction using UCI Cleveland dataset with data validation, multi-strategy feature engineering, and hyperparameter optimization. Data flows from CSV through Great Expectations validation, then splits into three parallel pipelines: base features, PCA-reduced (5 components), and LDA-reduced (1 component), each training four models including Perceptron, Decision Tree, and Random Forest. Optuna optimizes hyperparameters with 5-fold cross-validation while MLflow tracks metrics, parameters, and artifacts for reproducibility. The best model registers in MLflow Model Registry and deploys via Streamlit app with drift detection, containerized in Docker, and hosted on AWS ECR with ECS Fargate for scalable inference. This architecture demonstrates production-grade MLOps best practices: automated validation, experiment tracking, model registry, and cloud-native deployment.
People also ask
How do I build a production MLOps pipeline with data validation, hyperparameter tuning, and AWS deployment?
This diagram shows a complete MLOps workflow: UCI Cleveland heart data validates via Great Expectations, branches into three feature pipelines (base, PCA, LDA), trains four models with Optuna hyperparameter optimization and 5-fold cross-validation, tracks experiments in MLflow, registers the best model, deploys via Streamlit with drift detection, containerizes in Docker, and scales on AWS ECS Farg
- Domain:
- Ml Pipeline
- Audience:
- ML engineers and data scientists building production MLOps pipelines on AWS
Generated by Diagrams.so — AI architecture diagram generator with native Draw.io output. Fork this diagram, remix it, or download as .drawio, PNG, or SVG.