DFF Adapter Neural Module
About This Architecture
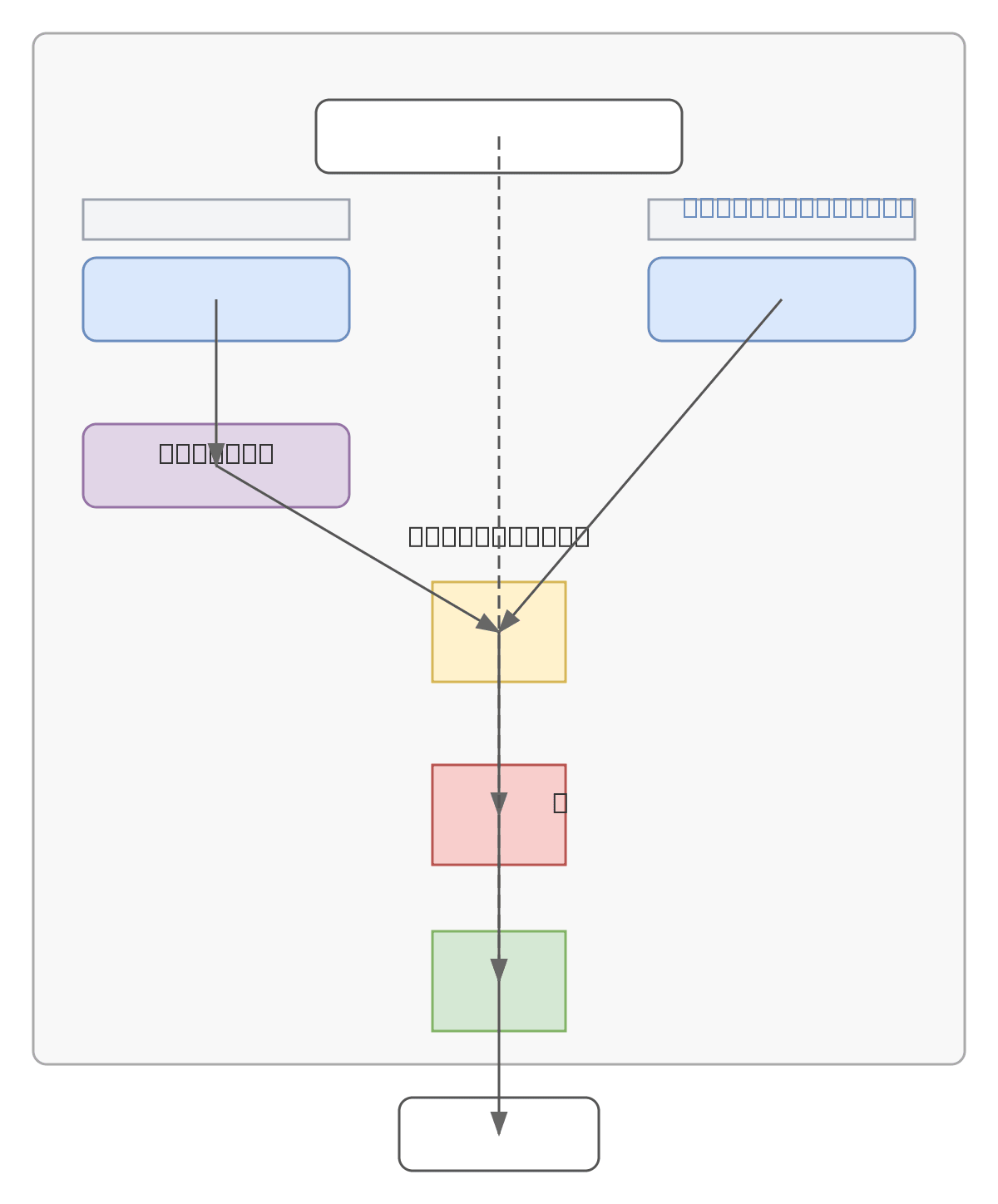
DFF Adapter Neural Module implements a dual-branch attention architecture combining learned feature scoring with adaptive enhancement. Input tensor X (batch × sequence × channels) flows through parallel Attention and Feature branches: the Attention branch applies Score MLP followed by Softmax normalization to compute attention weights, while the Feature branch uses Enhance MLP to transform features. Element-wise multiplication (⊙) combines weighted features, which pass through a gating function σ(g) before residual addition with the original input to produce output Y. This architecture enables efficient feature recalibration and selective information flow, commonly used in transformer-based models and modern deep learning frameworks. Fork and customize this diagram on Diagrams.so to adapt it for your specific model architecture or documentation needs.
People also ask
How does the DFF Adapter neural module combine attention scoring and feature enhancement?
The DFF Adapter uses parallel Attention and Feature branches: the Attention branch computes normalized weights via Score MLP and Softmax, while the Feature branch applies Enhance MLP. These branches merge through element-wise multiplication, pass through a gating function, and add residually to the input, enabling selective feature recalibration in transformer and deep learning models.
- Domain:
- Ml Pipeline
- Audience:
- Machine learning engineers implementing attention mechanisms and neural adapter modules
Generated by Diagrams.so — AI architecture diagram generator with native Draw.io output. Fork this diagram, remix it, or download as .drawio, PNG, or SVG.