x64 NPU Architecture - AI/ML Inference
About This Architecture
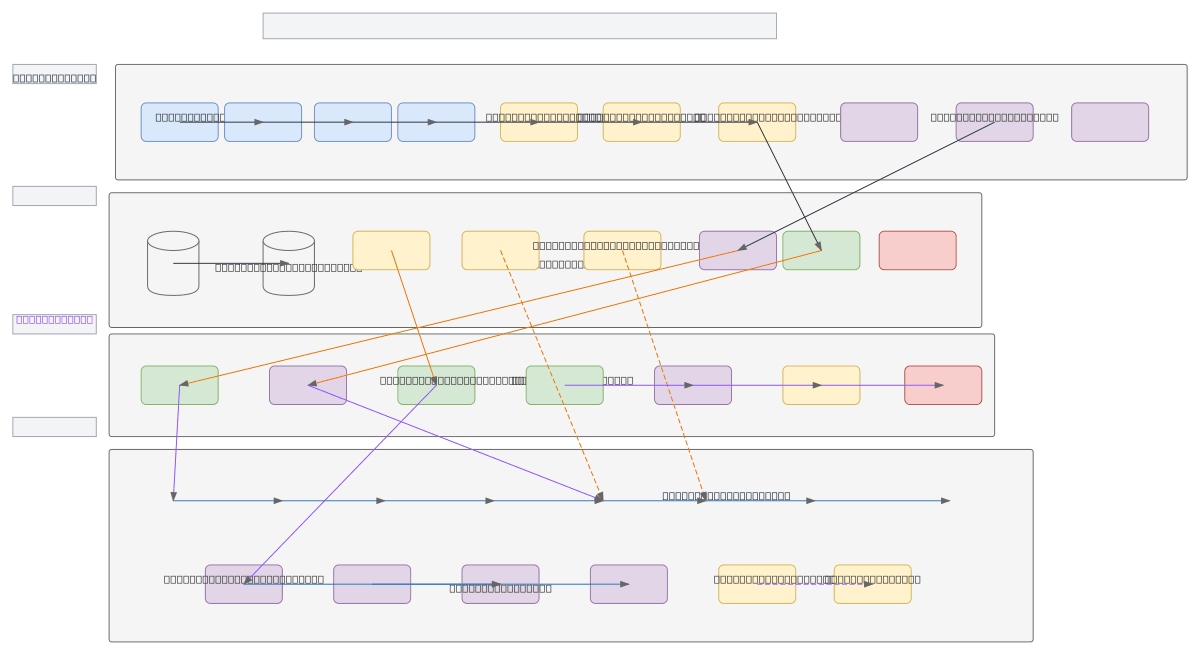
x64 NPU architecture combines quad-core x64 CPU complex with dedicated NPU core array for high-throughput AI/ML inference acceleration. Host CPU manages scheduling and OS runtime while NPU cores execute tensor operations via MAC arrays, quantization engines, and SIMD units, connected through PCIe 5.0, AXI4 NoC, and CXL 2.0 coherency fabric. Memory hierarchy spans DDR5 main memory, HBM2e NPU-local memory, and multi-level SRAM buffers with DMA engine for efficient data movement and ECC protection. This heterogeneous compute design delivers low-latency inference by offloading matrix operations to specialized hardware while maintaining CPU control, addressing the performance and power efficiency demands of edge and datacenter AI workloads. Fork this diagram on Diagrams.so to customize core counts, memory configurations, or interconnect protocols for your specific inference requirements.
People also ask
How does an x64 NPU architecture accelerate AI/ML inference with dedicated tensor cores and memory hierarchy?
x64 NPU architecture separates compute: quad-core x64 CPU handles scheduling and control via CPU Scheduler/OS Runtime, while NPU Core Array executes tensor operations through MAC arrays, quantization engines, and SIMD units. HBM2e NPU-local memory and multi-level SRAM buffers minimize data movement latency, connected via PCIe 5.0, AXI4 NoC, and CXL 2.0 coherency for efficient inference throughput.
- Domain:
- Ml Pipeline
- Audience:
- AI/ML hardware architects and systems engineers designing NPU-accelerated inference platforms
Generated by Diagrams.so — AI architecture diagram generator with native Draw.io output. Fork this diagram, remix it, or download as .drawio, PNG, or SVG.