TTS Architecture Comparison: Transformer vs
About This Architecture
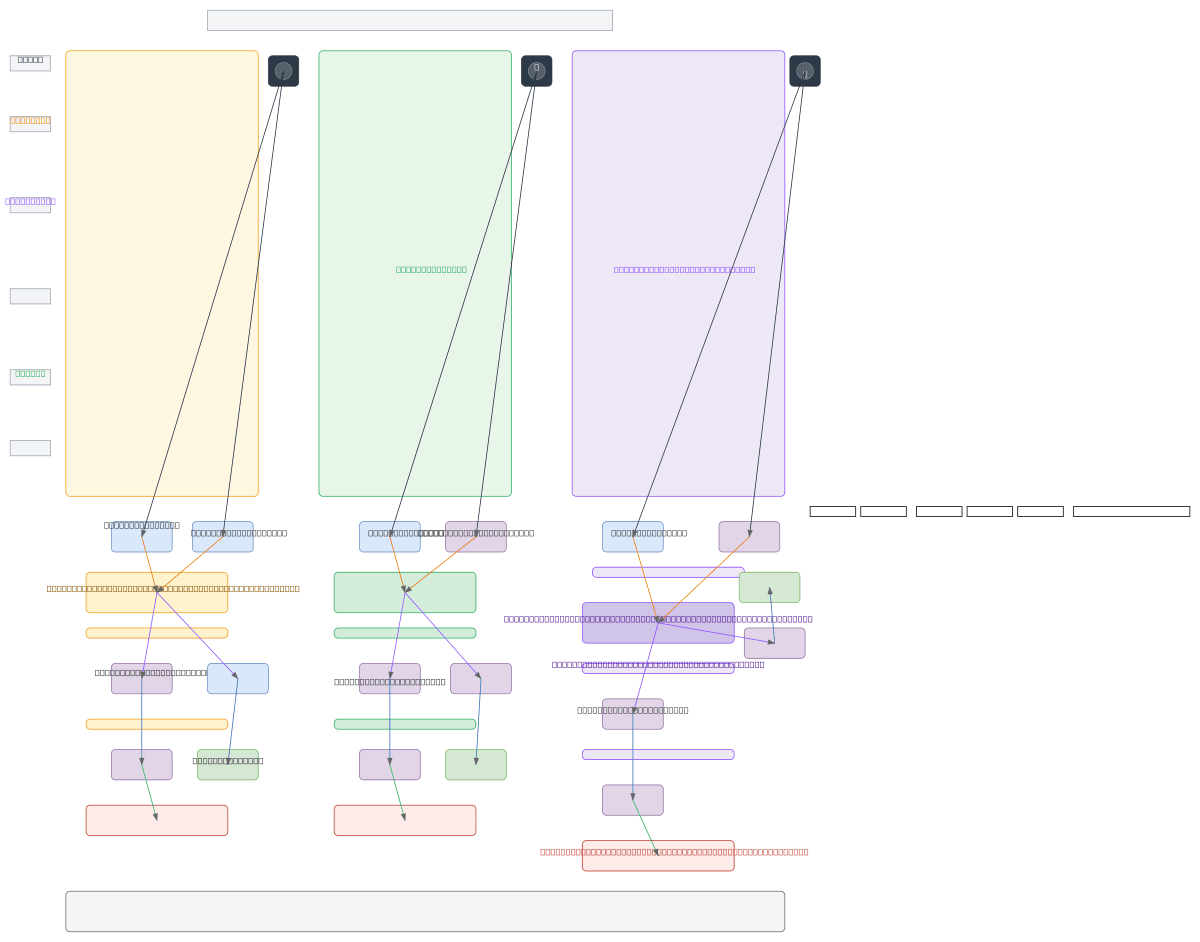
Transformer-TTS vs. NaturalSpeech3 vs. Discrete Event TTS: three competing neural architectures for high-fidelity speech synthesis. The diagram contrasts continuous mel-spectrogram prediction (Transformer-TTS with PostNet vocoder), discrete codec token diffusion (NaturalSpeech3 with VQ-VAE), and proposed event-level autoregressive generation (Discrete Event TTS with neural synthesizer). Each pipeline flows from phoneme encoding through acoustic modeling to waveform reconstruction, with distinct loss functions and token representations. Understanding these trade-offs—attention mechanisms, codec quantization, and event tokenization—is critical for selecting the right TTS architecture for latency, quality, and expressiveness requirements. Fork this diagram on Diagrams.so to customize component choices, add OCI compute resources, or benchmark inference costs across architectures.
People also ask
What are the key differences between Transformer-TTS, NaturalSpeech3, and event-based TTS architectures?
Transformer-TTS uses continuous mel-spectrogram prediction with PostNet refinement and vocoder synthesis; NaturalSpeech3 applies diffusion models over discrete codec tokens (EnCodec/SoundStream) for high-fidelity reconstruction; Discrete Event TTS proposes token-level autoregressive generation of onset, pitch, and duration events fed to a neural synthesizer. Each trades off inference speed, audio
- Domain:
- Ml Pipeline
- Audience:
- Machine learning engineers designing text-to-speech systems on OCI
Generated by Diagrams.so — AI architecture diagram generator with native Draw.io output. Fork this diagram, remix it, or download as .drawio, PNG, or SVG.