Transformer Encoder-Decoder Architecture
About This Architecture
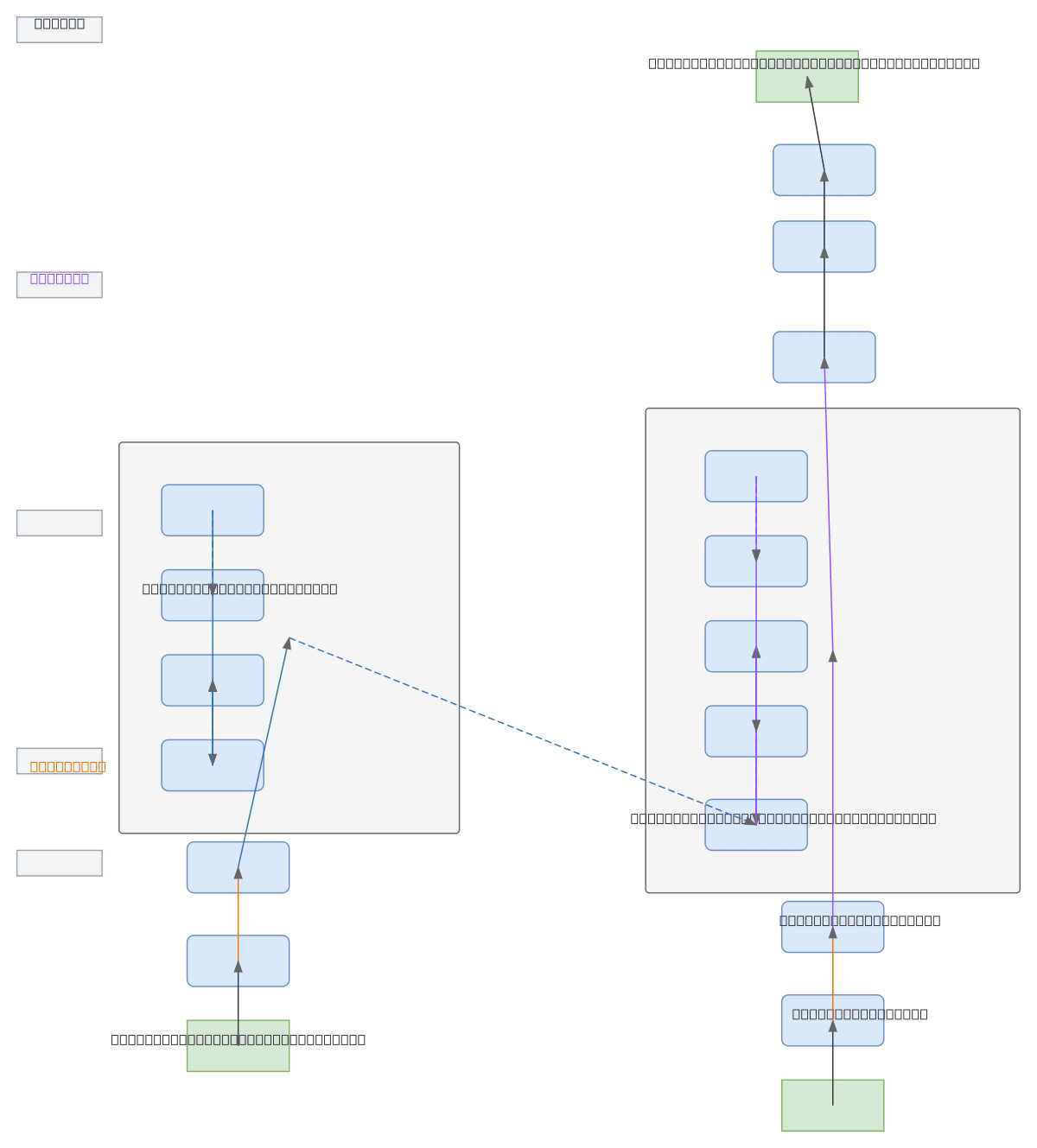
Transformer encoder-decoder architecture with stacked multi-head self-attention, cross-attention, and feed-forward layers for sequence-to-sequence tasks. Source tokens flow through input embedding and positional encoding into an N-layer encoder stack using masked self-attention and residual connections, while target tokens follow a parallel path through the decoder with cross-attention to encoder outputs. The decoder stack projects attention outputs through a linear layer and softmax to generate token probabilities, enabling machine translation, summarization, and other conditional generation tasks. Fork this diagram on Diagrams.so to customize layer counts, embedding dimensions, or attention head configurations for your OCI-hosted model training pipeline. This architecture demonstrates the complete transformer pattern with residual connections and layer normalization essential for stable training of large language models.
People also ask
How does a transformer encoder-decoder architecture work with multi-head attention and positional encoding?
The encoder processes source tokens through input embedding and positional encoding, then applies N stacked layers of multi-head self-attention and feed-forward networks with residual connections. The decoder receives target tokens through a similar embedding path and uses masked self-attention, cross-attention to encoder outputs, and feed-forward layers to generate output token probabilities via
- Domain:
- Ml Pipeline
- Audience:
- ML engineers and data scientists building transformer-based NLP models on OCI
Generated by Diagrams.so — AI architecture diagram generator with native Draw.io output. Fork this diagram, remix it, or download as .drawio, PNG, or SVG.