Speech Recognition Transformer Architecture
About This Architecture
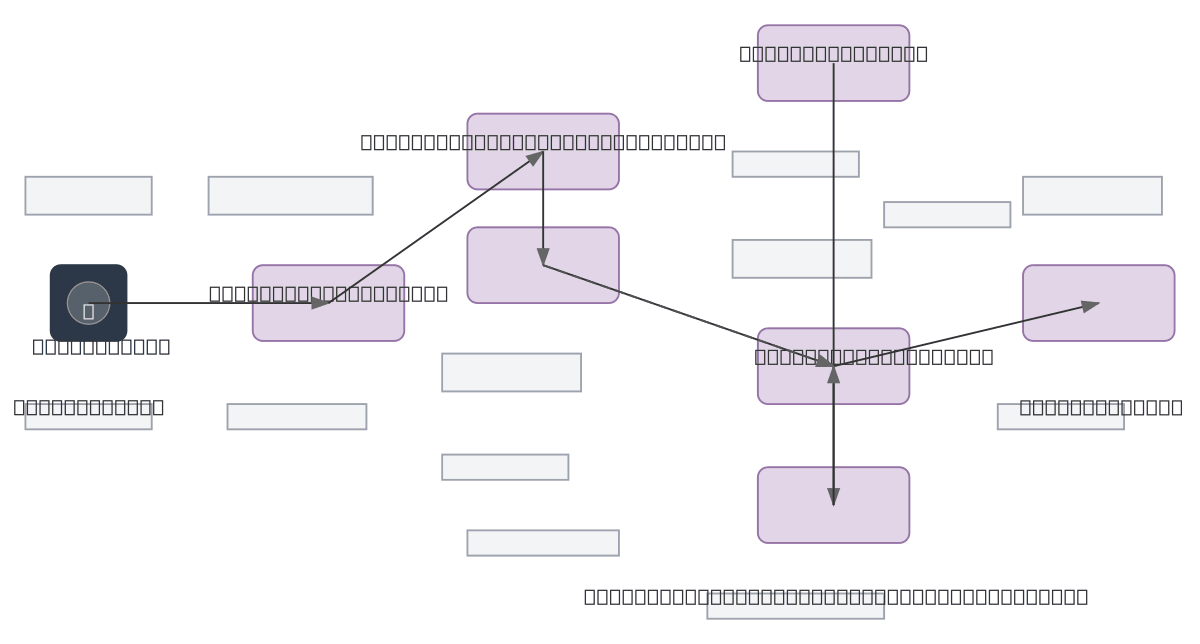
Speech recognition transformer architecture processes raw audio through log-mel spectrogram feature extraction, positional encoding, and a multi-layer encoder-decoder transformer stack. Audio input flows through feature extraction and positional encoding into the transformer encoder with N layers of self-attention, then cross-attends with previous tokens in the decoder's masked self-attention and cross-attention layers. This end-to-end sequence-to-sequence model converts spoken audio directly to text transcription with attention mechanisms capturing long-range dependencies. Fork and customize this diagram on Diagrams.so to document your OCI-hosted speech recognition pipeline, adjust layer counts, or integrate with OCI Data Science services.
People also ask
How does a transformer architecture convert speech audio to text using encoder-decoder attention?
A speech recognition transformer extracts log-mel spectrograms from raw audio, encodes them with positional encoding through N-layer self-attention, then decodes previous tokens via masked self-attention and cross-attention to generate text transcription. This architecture captures long-range acoustic dependencies and token relationships for accurate end-to-end speech-to-text conversion.
- Domain:
- Ml Pipeline
- Audience:
- Machine learning engineers building speech recognition systems on OCI
Generated by Diagrams.so — AI architecture diagram generator with native Draw.io output. Fork this diagram, remix it, or download as .drawio, PNG, or SVG.