Sign Language Recognition - Dual Model
About This Architecture
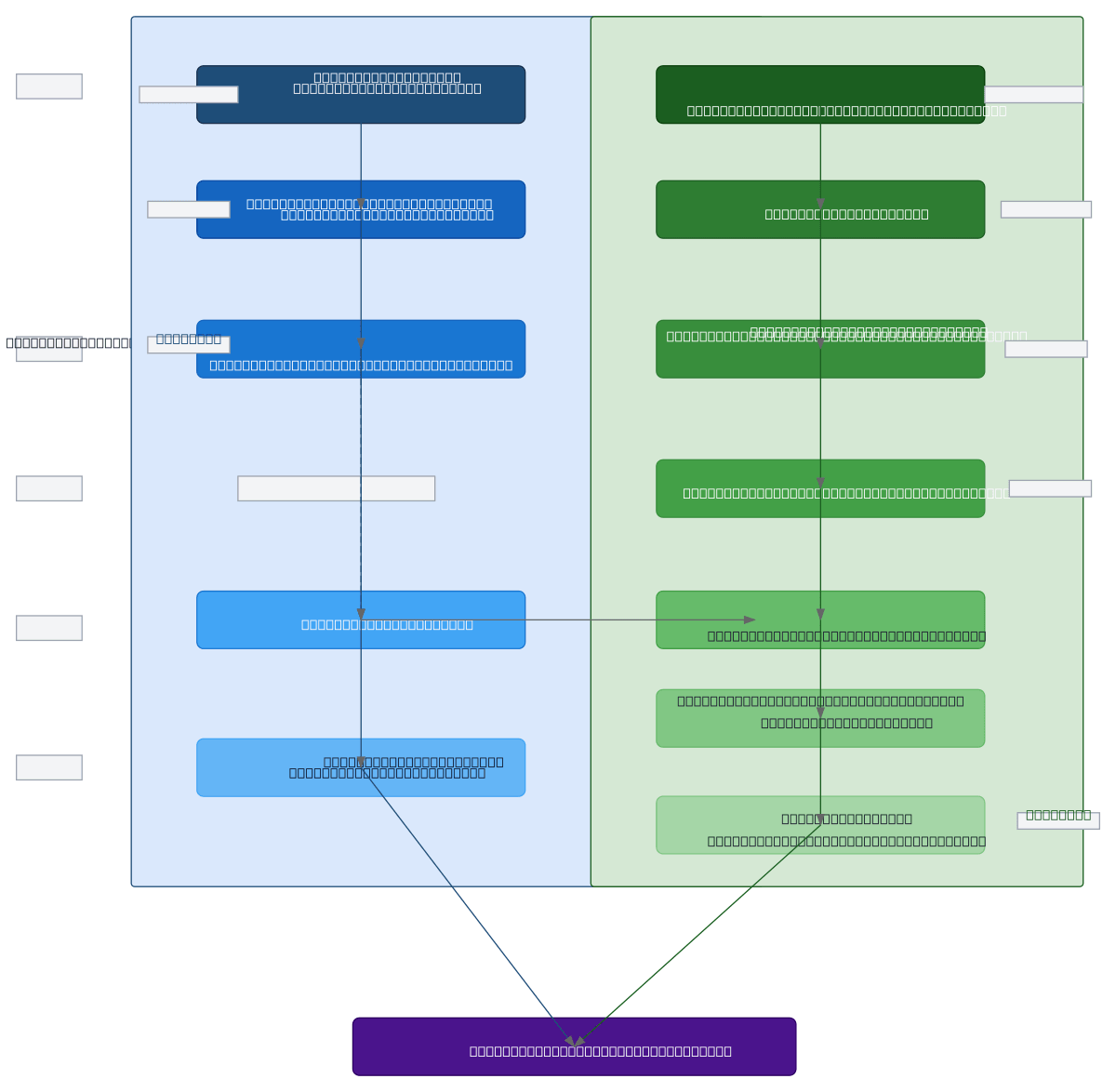
Dual-model architecture for sign language recognition comparing a baseline ResNet18+LSTM pipeline against an advanced ResNet50+BiLSTM+Attention system. The baseline model extracts per-frame spatial features via ResNet18, models temporal dependencies with single-layer LSTM (hidden size 256), and classifies via fully connected layer and softmax. The advanced model upgrades to ResNet50 for deeper feature extraction, stacks bidirectional LSTM layers (2 layers, 256 hidden per direction), and adds multi-head attention (8 heads, d_model 512) with 0.5 dropout regularization for improved robustness. Both pipelines process 16-frame video tensors (B, T=16, C=3, H=224, W=224) and output class probability distributions across 502 sign classes. This comparison enables practitioners to evaluate accuracy, loss, and inference speed trade-offs when selecting the optimal model for production deployment. Fork and customize this diagram on Diagrams.so to adapt layer configurations, attention mechanisms, or feature extraction backbones for your sign language dataset.
People also ask
What is the difference between baseline and advanced deep learning architectures for sign language recognition?
The baseline model uses ResNet18 for spatial feature extraction followed by single-layer LSTM for temporal modeling, while the advanced model upgrades to ResNet50, stacks bidirectional LSTM layers, and adds multi-head attention with dropout regularization. This diagram shows how attention mechanisms and bidirectional processing improve temporal understanding of hand gestures across 16-frame video
- Domain:
- Ml Pipeline
- Audience:
- Machine learning engineers building computer vision models for sign language recognition
Generated by Diagrams.so — AI architecture diagram generator with native Draw.io output. Fork this diagram, remix it, or download as .drawio, PNG, or SVG.