Pronunciation Assessment Pipeline
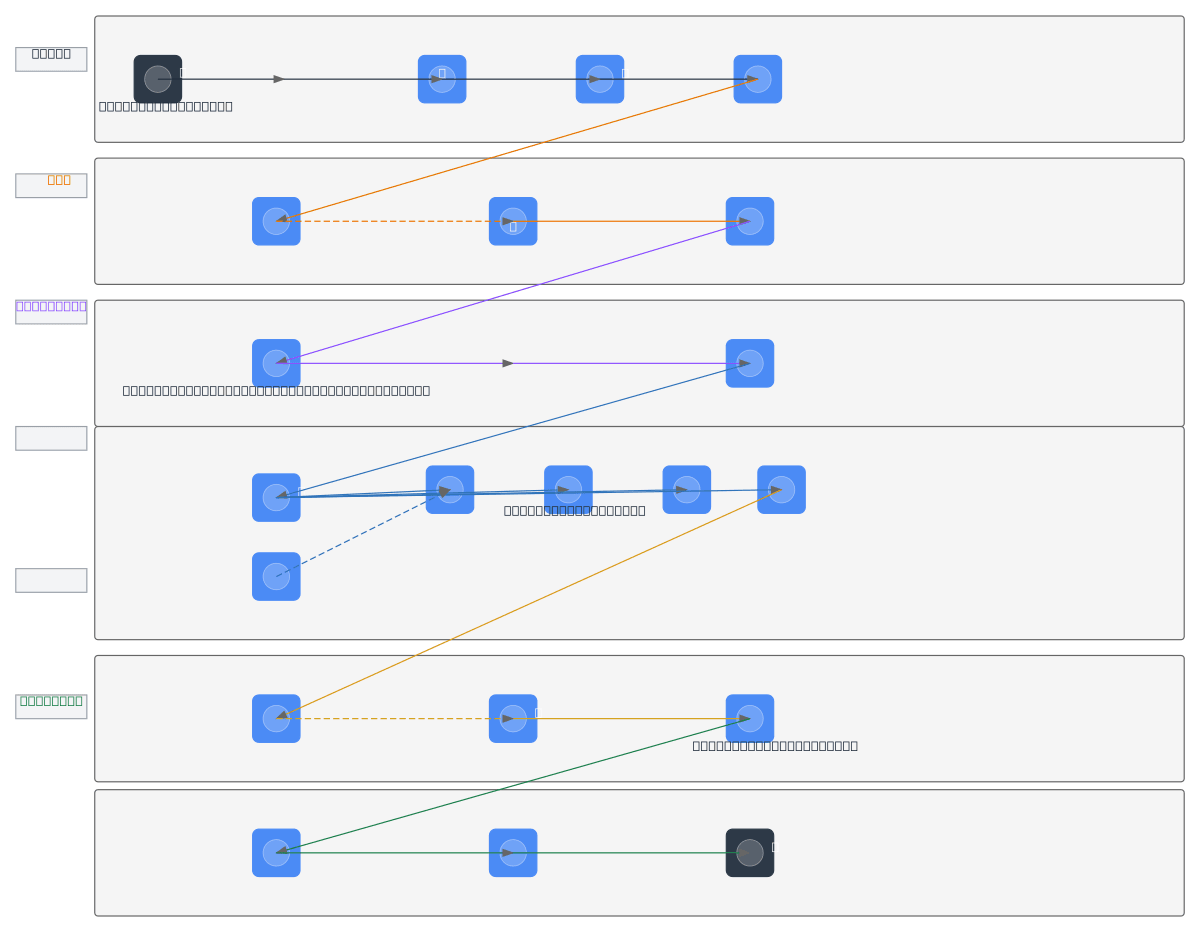
About This Architecture
End-to-end pronunciation assessment pipeline combining audio preprocessing, speech-to-text transcription, phonetic alignment, and AI-driven mispronunciation detection. Audio flows from user microphone through PyAudio recording and Librosa feature extraction (MFCC, pitch, RMS, mel spectrograms) into dual STT options: local Whisper model or Google Cloud STT API. Phonetic conversion via CMU Pronouncing Dictionary generates ARPAbet sequences aligned against detected speech using wav2vec, SpeechBrain CAPT, and Speechocean models to identify substitutions, deletions, insertions, and stress errors. LoRA phi-4 deep model synthesizes accuracy scores, which pyttsx3 TTS converts into audio feedback played back to the user. This architecture demonstrates production-grade speech processing combining open-source and commercial components for scalable language learning applications. Fork and customize this diagram on Diagrams.so to adapt STT providers, phonetic databases, or scoring models for your specific language or assessment use case.
People also ask
How do you build an end-to-end pronunciation assessment system that detects mispronunciations and provides automated feedback?
This diagram shows a complete pipeline: capture audio via PyAudio, extract MFCC and mel spectrogram features with Librosa, transcribe with Whisper or Google Cloud STT, align phonemes using CMU Pronouncing Dictionary and ARPAbet, detect errors (substitution, deletion, insertion) with wav2vec and SpeechBrain CAPT, score accuracy with Speechocean and LoRA phi-4, and deliver audio feedback via pyttsx3
- Domain:
- Ml Pipeline
- Audience:
- ML engineers building speech assessment systems and pronunciation evaluation platforms
Generated by Diagrams.so — AI architecture diagram generator with native Draw.io output. Fork this diagram, remix it, or download as .drawio, PNG, or SVG.