Oracle to Snowflake Migration Pipeline
About This Architecture
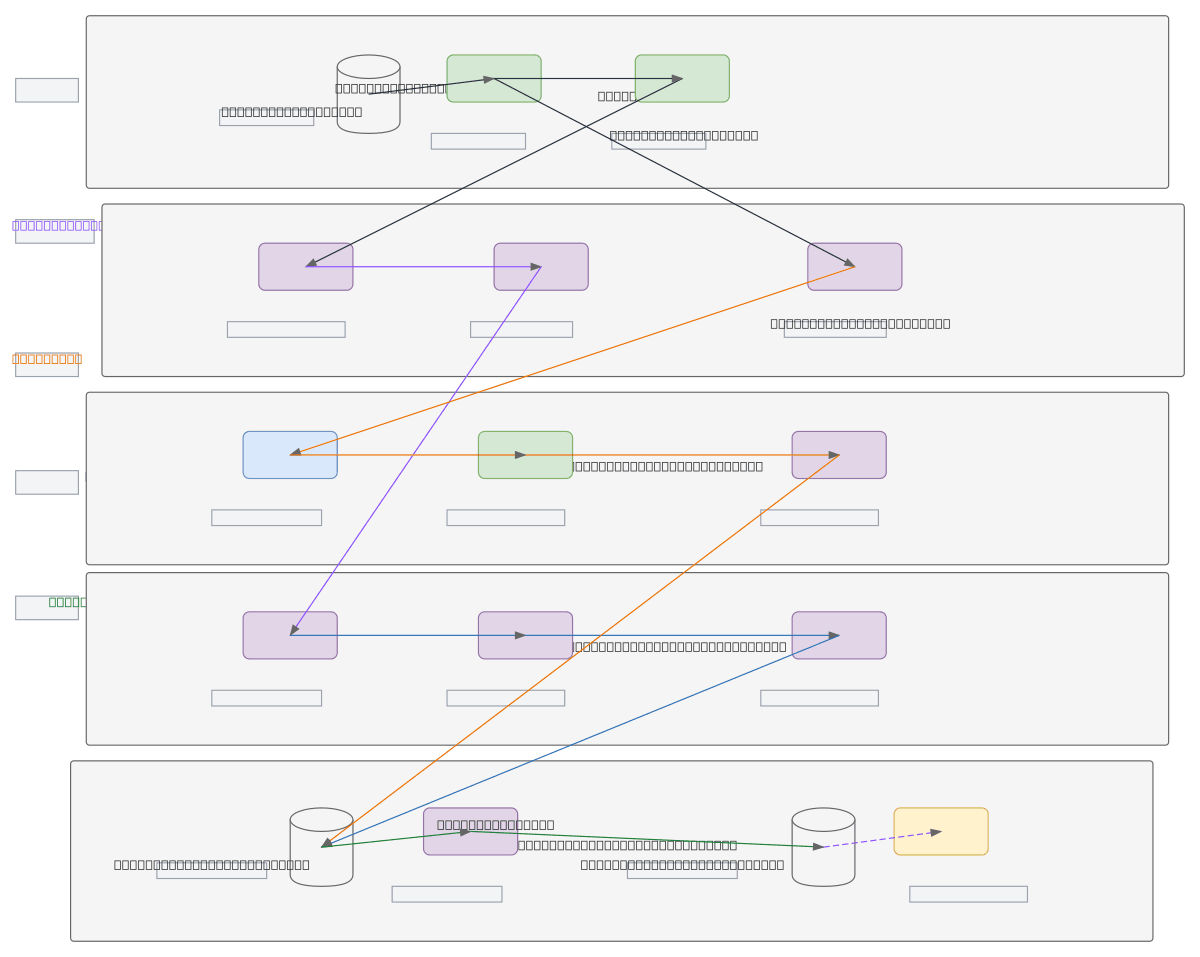
Oracle-to-Snowflake migration pipeline combining batch and real-time CDC ingestion into a medallion architecture. Oracle Redo Logs feed Oracle CDC (LogMiner/GoldenGate) and Debezium Connector, which streams changes via Apache Kafka to Snowpipe Streaming, while Airflow orchestrates Apache Spark batch extracts to S3/ADLS staging for bulk COPY INTO loads. Raw data lands in Snowflake's Raw Layer, transforms via dbt into curated Gold Layer tables, with Query History and Alerts monitoring end-to-end pipeline health. This architecture minimizes downtime during cutover, supports incremental syncs post-migration, and leverages Snowflake's native Snowpipe for zero-copy ingestion. Fork this diagram to customize connector configs, adjust batch schedules, or add data quality checks between layers.
People also ask
How do I design an Oracle to Snowflake migration pipeline that handles both initial bulk loads and ongoing CDC syncs?
This diagram shows a dual-path approach: Airflow triggers Apache Spark batch jobs for initial Oracle table extracts to S3/ADLS staging, then bulk-loads via Snowflake COPY INTO, while Debezium Connector captures Oracle Redo Logs and streams changes through Kafka to Snowpipe Streaming for real-time Raw Layer ingestion. dbt then transforms Raw data through curated Gold layers with monitoring via Snow
- Domain:
- Data Engineering
- Audience:
- Data engineers designing Oracle-to-Snowflake migration pipelines
Generated by Diagrams.so — AI architecture diagram generator with native Draw.io output. Fork this diagram, remix it, or download as .drawio, PNG, or SVG.