Multi-Source Data Platform - ETL and Archive
About This Architecture
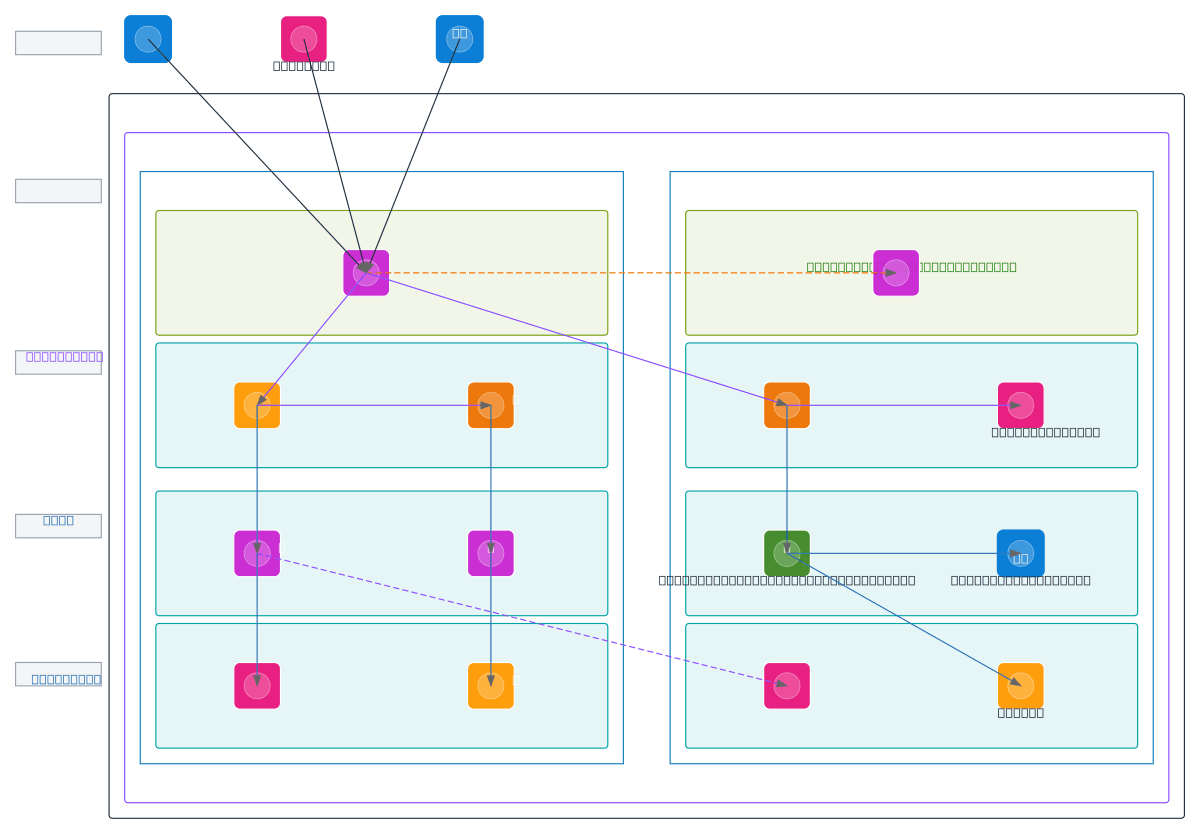
Multi-source ETL platform ingesting operational data from PostgreSQL, Azure, and AWS APIs into a VPC-isolated AWS infrastructure spanning two availability zones. Raw data flows through transformation pipelines via Lambda and Step Functions, populating analytical PostgreSQL and Redshift for reporting while archiving compressed snapshots to S3 and Azure Blob Storage. This architecture demonstrates hybrid cloud data consolidation with separation of concerns across processing, analytics, and archive subnets. Fork and customize this diagram on Diagrams.so to adapt multi-region failover, adjust Lambda concurrency, or integrate additional data sources. The dual-archive strategy (S3 + Azure Blob) provides compliance flexibility and disaster recovery across cloud providers.
People also ask
How do I design a multi-cloud ETL platform that ingests from multiple sources, transforms data with AWS Lambda, and archives to both S3 and Azure Blob?
This diagram shows a production ETL architecture where Raw PostgreSQL (Operational) feeds Transformation/ETL pipelines via Lambda and Step Functions, populating Analytical PostgreSQL and Redshift for reporting. Snapshot Archiver Job orchestrates compressed snapshots to S3 Archive and Azure Blob Archive, enabling compliance and disaster recovery across AWS and Azure.
- Domain:
- Data Engineering
- Audience:
- Data engineers designing multi-cloud ETL pipelines with hybrid storage and analytics
Generated by Diagrams.so — AI architecture diagram generator with native Draw.io output. Fork this diagram, remix it, or download as .drawio, PNG, or SVG.