MoE Speaker Recognition - ECAPA-TDNN Experts
About This Architecture
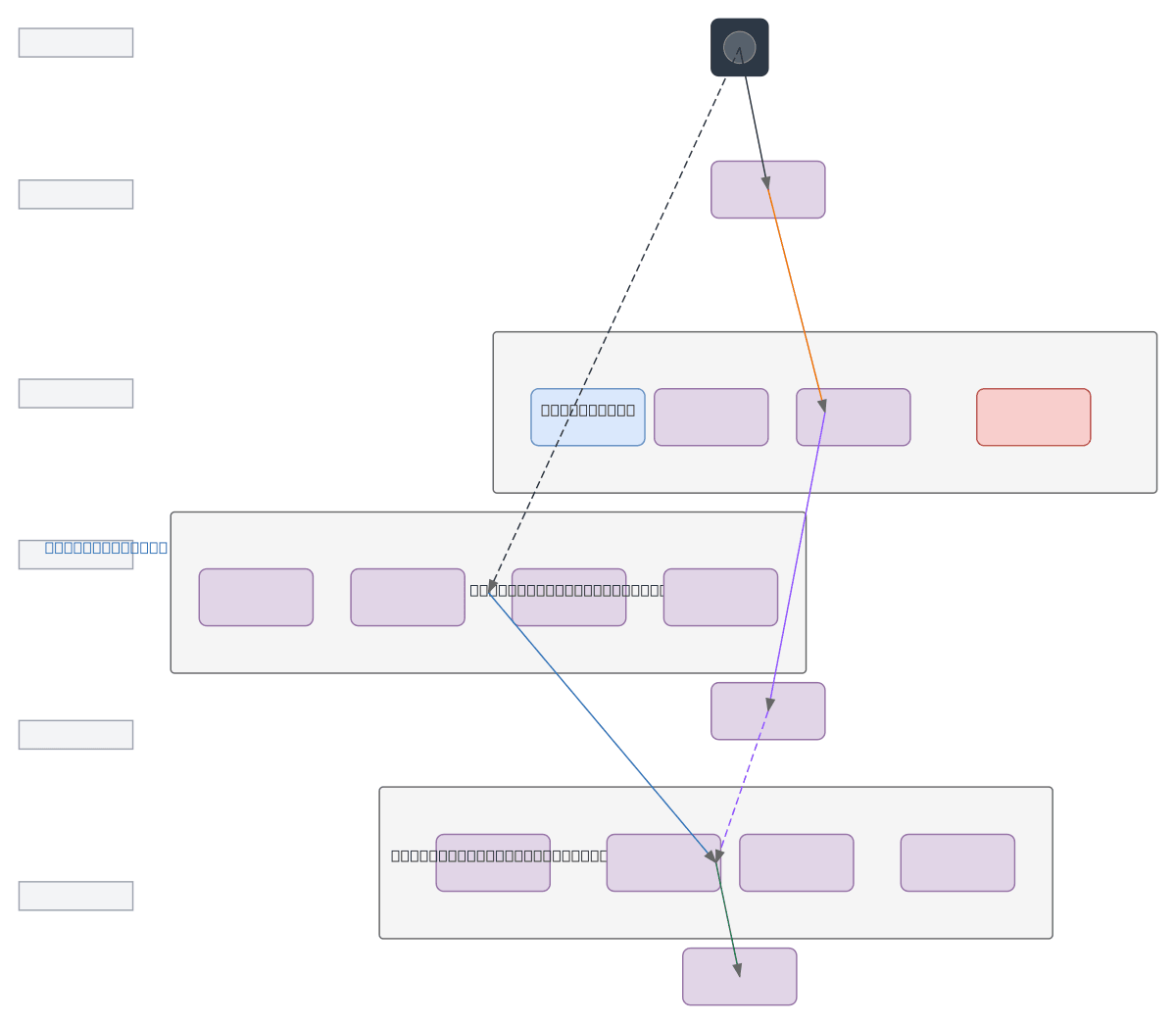
Mixture-of-Experts speaker recognition system using ECAPA-TDNN experts with dynamic routing via gating network. Raw audio is transformed to Mel-spectrograms and fed to a CNN-based gating network that learns expert weights, while parallel ECAPA-TDNN experts extract speaker embeddings. Weighted feature aggregation combines expert outputs, normalized to speaker embedding vectors, then classified via AAMSoftmax or ArcFace loss. This MoE approach improves speaker verification accuracy by routing different acoustic patterns to specialized experts, enabling better generalization across diverse speaker populations. Fork and customize this architecture on Diagrams.so to experiment with expert counts, gating mechanisms, or loss functions for your speaker recognition pipeline.
People also ask
How does a mixture-of-experts architecture improve speaker recognition with ECAPA-TDNN models?
This diagram shows how a gating network routes Mel-spectrogram features to multiple ECAPA-TDNN experts, each specializing in different acoustic patterns. Expert outputs are weighted and aggregated into normalized speaker embeddings, then classified with AAMSoftmax or ArcFace loss, enabling better generalization across diverse speakers.
- Domain:
- Ml Pipeline
- Audience:
- ML engineers building speaker recognition systems with mixture-of-experts architectures
Generated by Diagrams.so — AI architecture diagram generator with native Draw.io output. Fork this diagram, remix it, or download as .drawio, PNG, or SVG.