Job Intelligence Pipeline - Scraper to Matching
About This Architecture
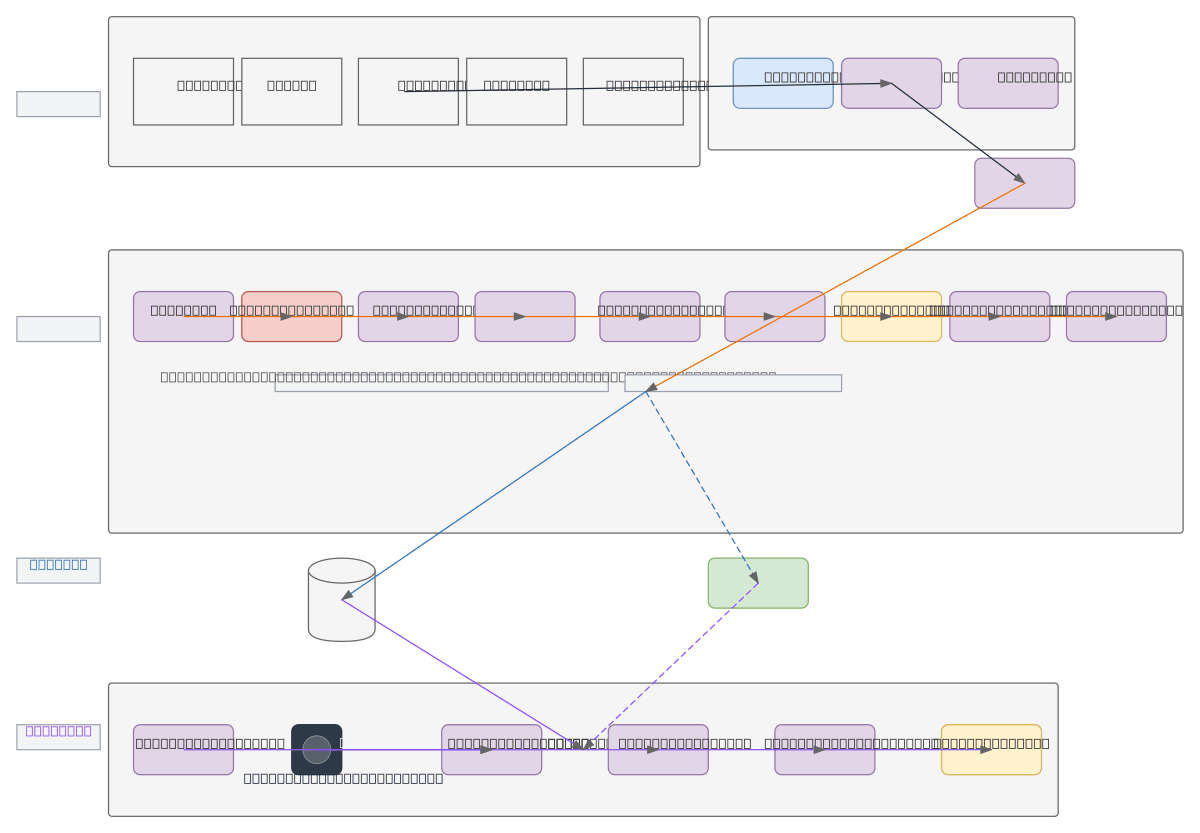
Job Intelligence Pipeline orchestrates end-to-end job scraping, NLP enrichment, and candidate-job matching across LinkedIn, Indeed, Glassdoor, and InfoJobs. Data flows from web scrapers through RabbitMQ into a processing pipeline that extracts skills, normalizes attributes, classifies sectors, and generates embeddings via NLP models. PostgreSQL with pgvector stores structured data and embeddings while MinIO archives metadata, feeding a matching engine that ranks candidates by similarity scores. This architecture demonstrates best practices for large-scale talent acquisition: decoupled ingestion via message brokers, semantic search with embeddings, and scalable vector storage. Fork this diagram on Diagrams.so to customize data sources, add additional job portals, or swap NLP models and vector databases.
People also ask
How do I build a job matching system that scrapes multiple job portals, extracts skills with NLP, and ranks candidates by semantic similarity?
This diagram shows a complete pipeline: Job Portals feed SCRAPERPRO into RabbitMQ, which distributes to a Classifier that extracts skills, normalizes attributes, and generates NLP embeddings stored in PostgreSQL with pgvector. The Matching Engine loads candidate profiles and uses a Similarity Engine to rank matches by score, outputting ranked recommendations.
- Domain:
- Data Engineering
- Audience:
- Data engineers building job matching and talent acquisition pipelines
Generated by Diagrams.so — AI architecture diagram generator with native Draw.io output. Fork this diagram, remix it, or download as .drawio, PNG, or SVG.