Feature Attention Module with Residual Gate
About This Architecture
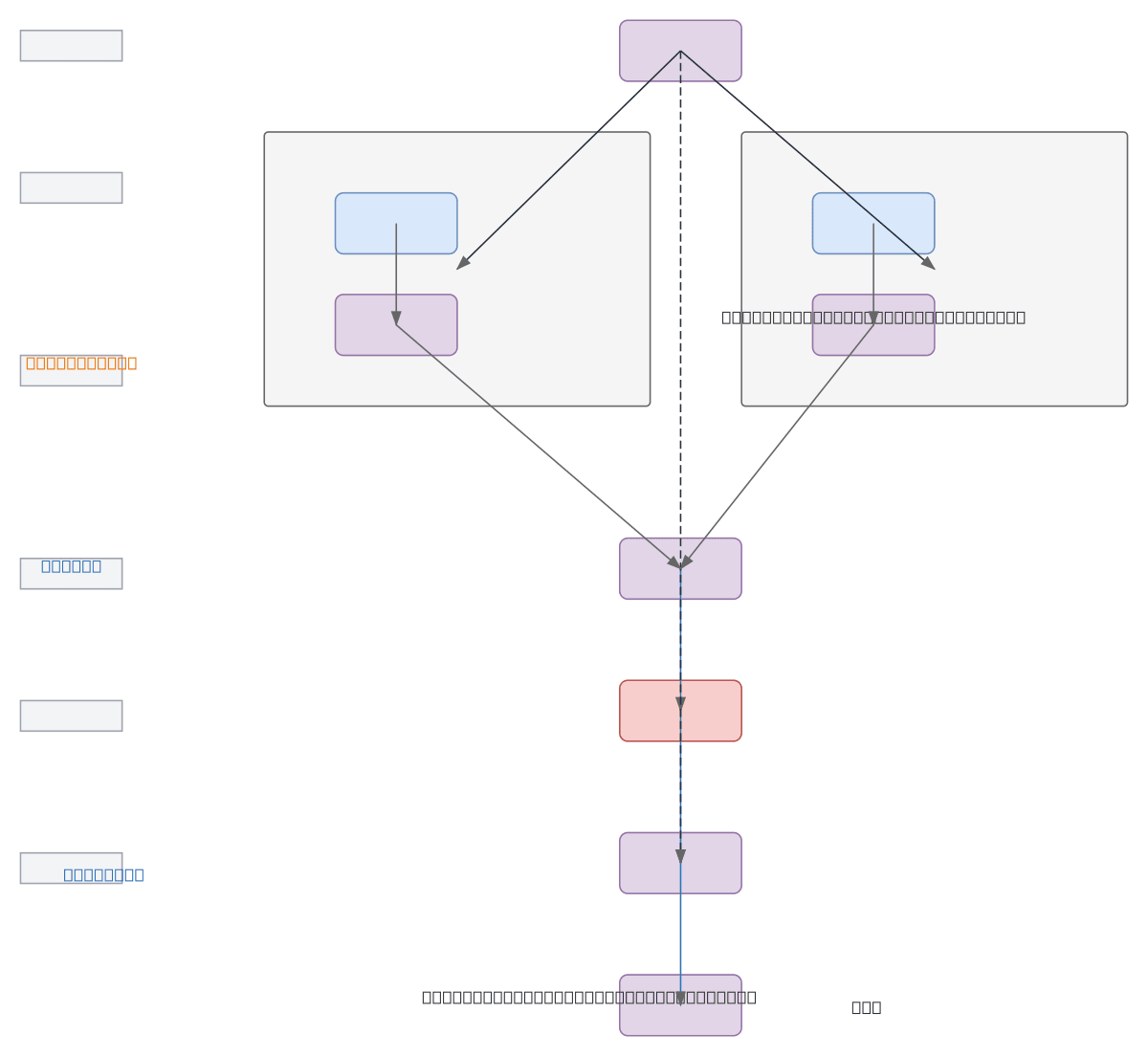
Feature Attention Module with Residual Gate combines dual-branch attention and feature enhancement to selectively amplify important input features. The Importance Branch generates attention scores via MLP and Softmax, while the Enhancement Branch produces refined features through learned transformations, with both streams merged via element-wise multiplication. A Sigmoid Gate controls the residual connection, enabling the network to learn when to apply attention-gated features or bypass them entirely. This architecture solves the problem of adaptive feature recalibration while maintaining gradient flow through residual connections. Fork this diagram on Diagrams.so to customize layer dimensions, activation functions, or integrate it into your transformer or CNN backbone.
People also ask
How does a Feature Attention Module with Residual Gate work in neural networks?
This architecture uses two parallel branches: an Importance Branch that generates attention scores via MLP and Softmax, and an Enhancement Branch that refines features through learned transformations. The attention scores and enhanced features are multiplied element-wise, passed through a Sigmoid Gate, and added back to the original input via a residual connection, enabling the network to adaptive
- Domain:
- Ml Pipeline
- Audience:
- Deep learning engineers and ML researchers implementing attention mechanisms in neural networks
Generated by Diagrams.so — AI architecture diagram generator with native Draw.io output. Fork this diagram, remix it, or download as .drawio, PNG, or SVG.