Enterprise Customer Analytics Data Flow
About This Architecture
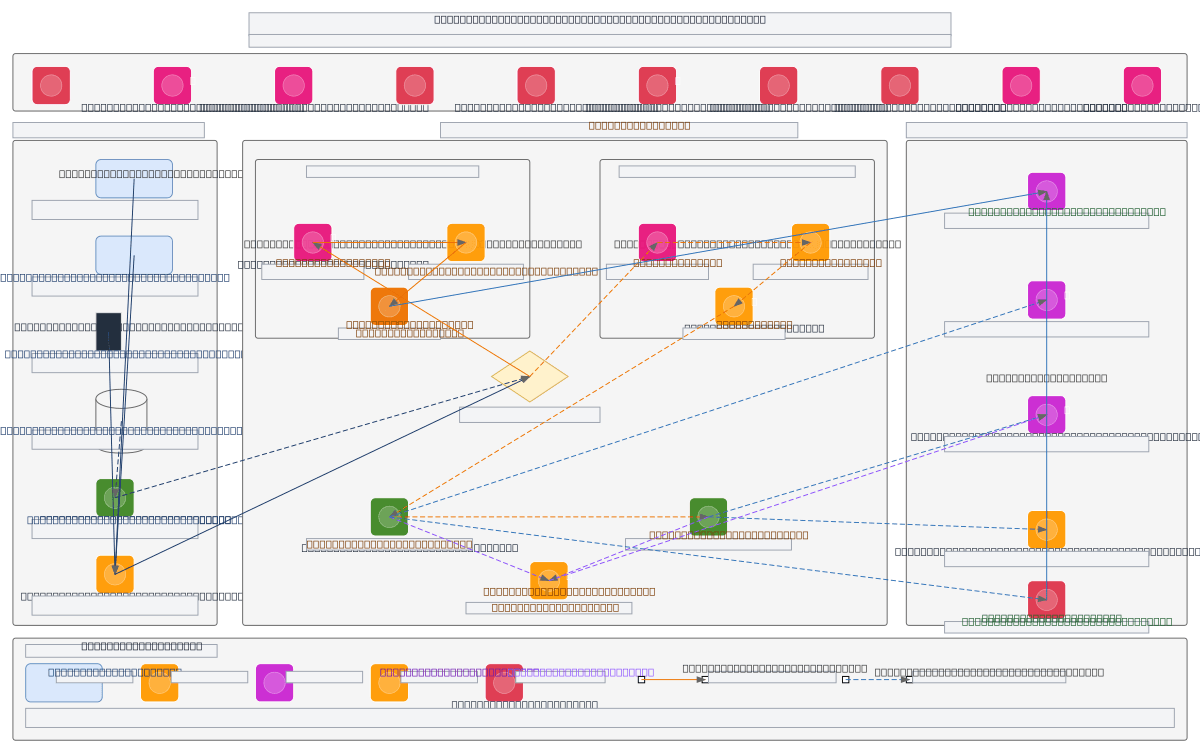
Enterprise-grade customer analytics data flow combining real-time fraud detection and batch segmentation across banking sources. Data flows from Core Banking, Online Banking, Mobile App, and Branch Systems through Kinesis and MSK into dual-path processing: Apache Flink CEP for sub-100ms fraud scoring and Apache Airflow-orchestrated Spark ETL for nightly customer segmentation. Raw events land in S3 Bronze tier, transform through Silver (dbt-curated) and Gold (aggregated) tiers, then route to operational Redis and analytical Snowflake/Redshift destinations. AWS Glue catalogs all layers while CloudWatch, CloudTrail, GuardDuty, and Macie enforce governance, encryption (TLS 1.3/AES-256), and compliance across the pipeline. Fork this diagram to customize data sources, add new destinations, or adjust latency thresholds for your regional bank architecture. The layered medallion approach with dual real-time and batch paths demonstrates how enterprises balance operational fraud prevention with strategic customer insights.
People also ask
How do I build a real-time fraud detection and batch customer segmentation pipeline on AWS for a regional bank?
This diagram shows a dual-path architecture: Kinesis ingests 50K–200K daily events from banking systems into Apache Flink for sub-100ms fraud scoring to Redis, while Apache Airflow orchestrates nightly Spark jobs transforming data through S3 Bronze/Silver/Gold tiers to Snowflake. AWS Glue catalogs all layers; CloudWatch, CloudTrail, GuardDuty, and Macie enforce encryption, compliance, and threat d
- Domain:
- Data Engineering
- Audience:
- Data engineers building enterprise analytics pipelines on AWS
Generated by Diagrams.so — AI architecture diagram generator with native Draw.io output. Fork this diagram, remix it, or download as .drawio, PNG, or SVG.