CNN-LSTM Cross-Attention Architecture
About This Architecture
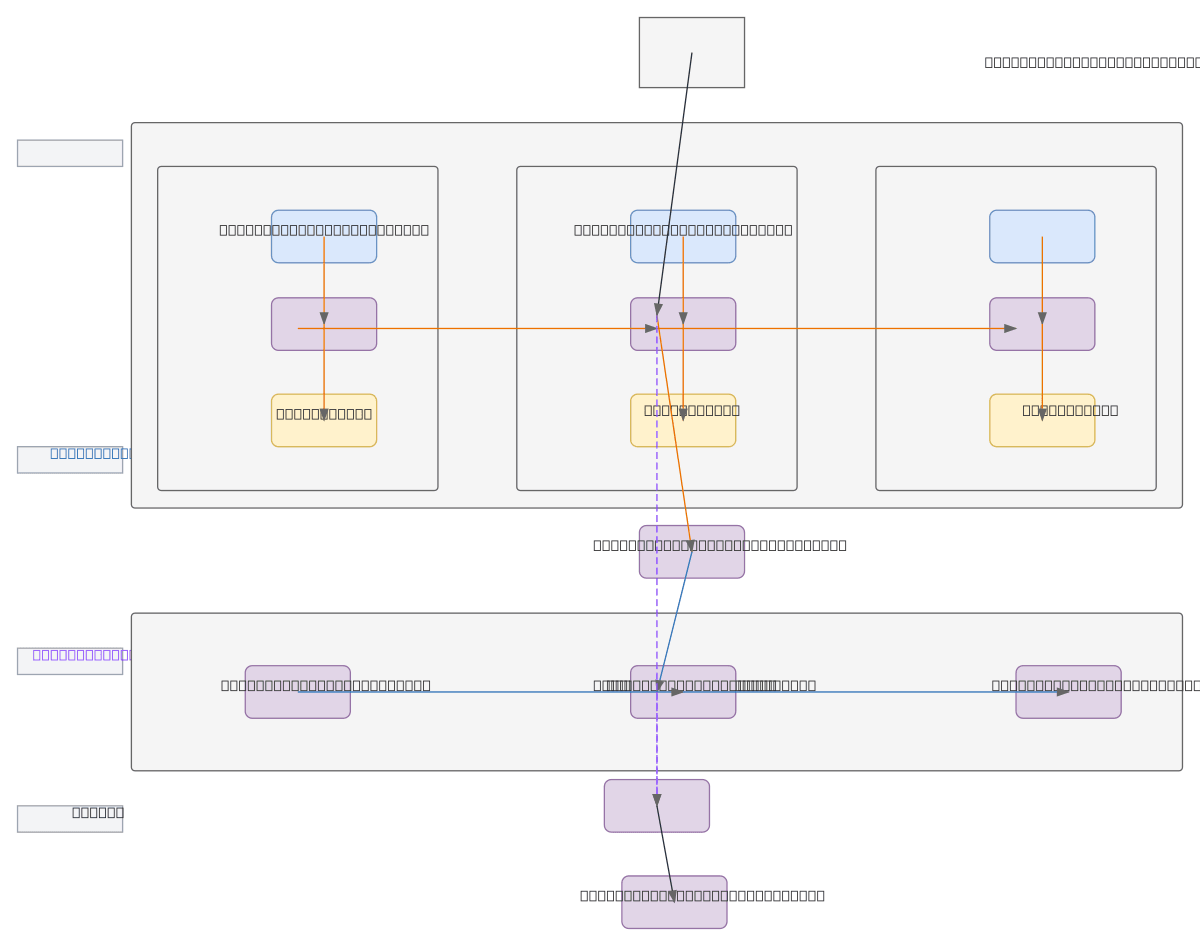
CNN-LSTM cross-attention architecture combines convolutional feature extraction with sequential modeling and learned attention mechanisms for image understanding tasks. A 224x224x3 input image flows through three CNN layers (64, 128, 256 filters with batch normalization and max pooling), flattened into a sequence, then processed by three stacked LSTM layers (256 units each) that learn temporal dependencies. The cross-attention module fuses CNN-extracted spatial features as keys and values with LSTM-generated queries, enabling the model to dynamically focus on relevant image regions during sequence processing. This hybrid approach excels at tasks requiring both spatial pattern recognition and temporal context, such as video action recognition, image captioning, or visual question answering. Fork and customize this diagram on Diagrams.so to adapt layer depths, filter counts, or attention mechanisms for your specific dataset and inference requirements.
People also ask
How do CNN-LSTM architectures with cross-attention mechanisms work for image and video understanding?
This diagram shows how a CNN feature extractor (three convolutional layers with 64, 128, and 256 filters) processes input images to capture spatial patterns, while an LSTM sequence encoder (three 256-unit layers) learns temporal dependencies. The cross-attention module bridges both pathways by using CNN features as keys/values and LSTM outputs as queries, enabling dynamic focus on relevant image r
- Domain:
- Ml Pipeline
- Audience:
- Machine learning engineers building multimodal deep learning models with CNN-LSTM architectures
Generated by Diagrams.so — AI architecture diagram generator with native Draw.io output. Fork this diagram, remix it, or download as .drawio, PNG, or SVG.