Classifier Distributor Subsystem Pipeline
About This Architecture
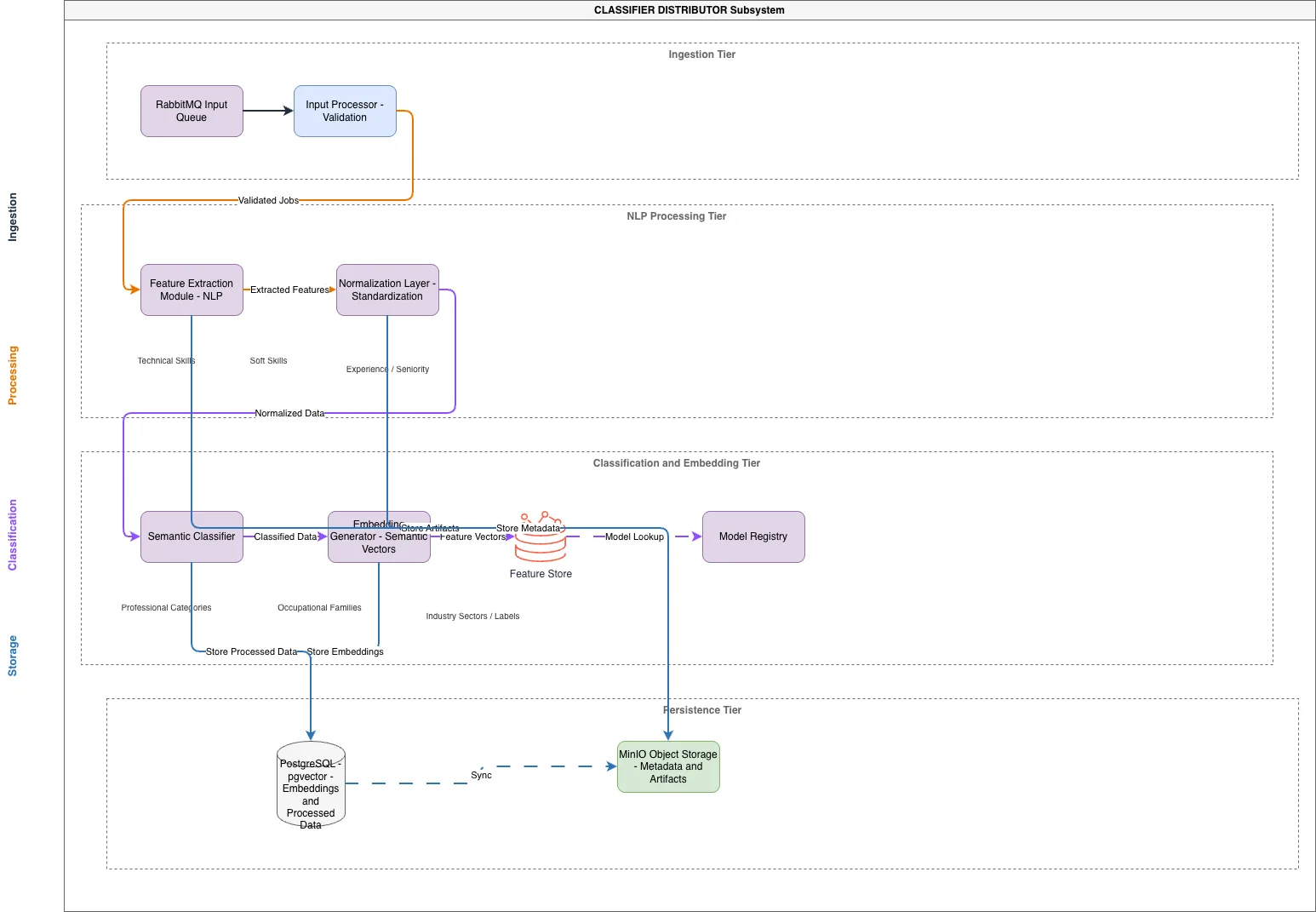
Classifier Distributor Subsystem Pipeline orchestrates end-to-end NLP-driven professional classification using RabbitMQ, feature extraction, semantic embeddings, and dual persistence layers. Data flows from RabbitMQ Input Queue through validation, NLP feature extraction (Technical Skills, Soft Skills, Experience/Seniority), normalization, and semantic classification into Professional Categories, Occupational Families, and Industry Sectors. The pipeline generates semantic vectors via Embedding Generator, storing embeddings and metadata in PostgreSQL with pgvector and MinIO Object Storage while maintaining a Feature Store and Model Registry for reproducibility. This architecture enables scalable, production-grade classification with vector similarity search and artifact versioning for continuous model improvement.
People also ask
How do you build a scalable NLP classification pipeline with semantic embeddings and vector search?
This Classifier Distributor Subsystem Pipeline demonstrates a complete architecture: RabbitMQ ingests data, Input Processor validates, Feature Extraction Module extracts Technical/Soft Skills and Experience, Normalization Layer standardizes features, Semantic Classifier categorizes into Professional Categories and Industry Sectors, and Embedding Generator creates semantic vectors stored in Postgre
- Domain:
- Ml Pipeline
- Audience:
- ML engineers building NLP classification pipelines with semantic embeddings
Generated by Diagrams.so — AI architecture diagram generator with native Draw.io output. Fork this diagram, remix it, or download as .drawio, PNG, or SVG.