Classifier Distributor Subsystem Pipeline
About This Architecture
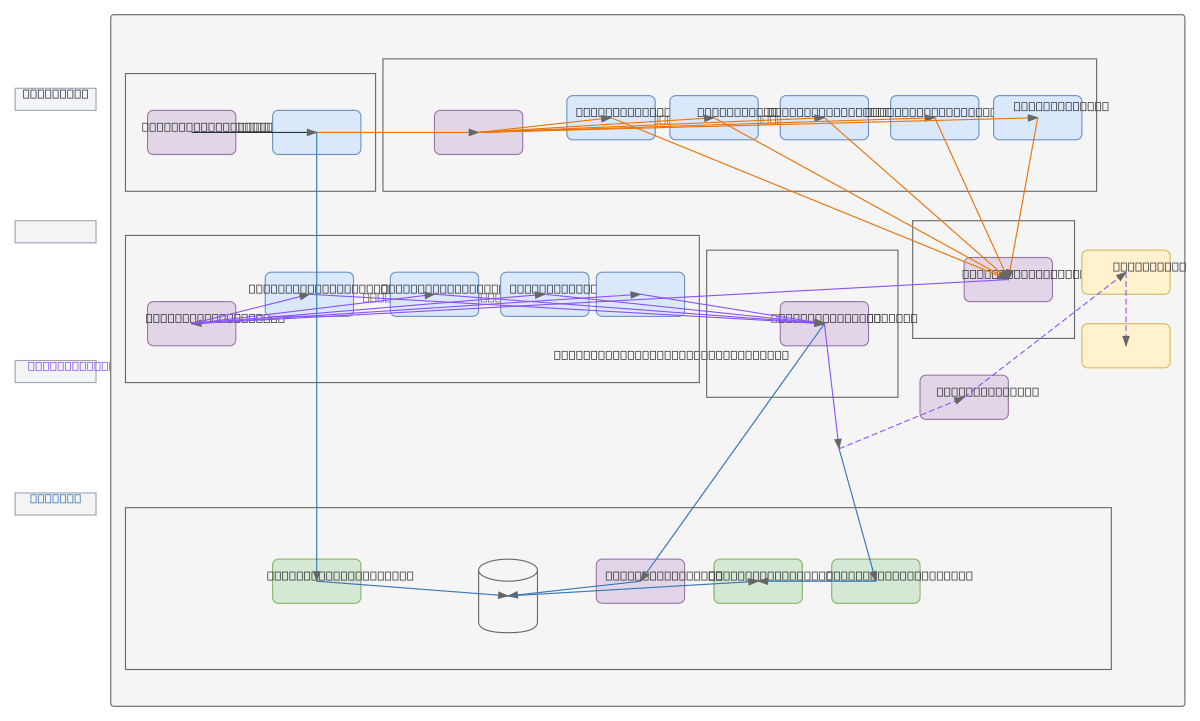
Classifier Distributor Subsystem Pipeline orchestrates end-to-end job offer classification using NLP feature extraction, semantic categorization, and vector embeddings. RabbitMQ ingests raw job data, flows through Feature Extraction Module (NLP) to extract technical skills, soft skills, experience, location, and salary attributes, then normalizes and classifies into professional categories, occupational families, industry sectors, and contextual labels. Embedding Generator produces vector representations stored in PostgreSQL with pgvector and MinIO, enabling semantic search and downstream ML applications. This architecture demonstrates best practices for scalable, modular data pipelines with clear separation of concerns: ingestion, feature engineering, classification, embedding, and storage layers. Fork this diagram on Diagrams.so to customize for your own classification domain, swap RabbitMQ for Kafka, or integrate alternative embedding models.
People also ask
How do you build a scalable NLP pipeline to classify job offers into professional categories and generate semantic embeddings?
This Classifier Distributor Subsystem Pipeline ingests job data via RabbitMQ, extracts features (skills, experience, salary) using NLP, normalizes attributes, classifies into occupational families and industry sectors, then generates vector embeddings stored in PostgreSQL with pgvector and MinIO for semantic search and ML applications.
- Domain:
- Data Engineering
- Audience:
- Data engineers building NLP-driven classification pipelines
Generated by Diagrams.so — AI architecture diagram generator with native Draw.io output. Fork this diagram, remix it, or download as .drawio, PNG, or SVG.