Chat Application - Enterprise Data Pipeline
About This Architecture
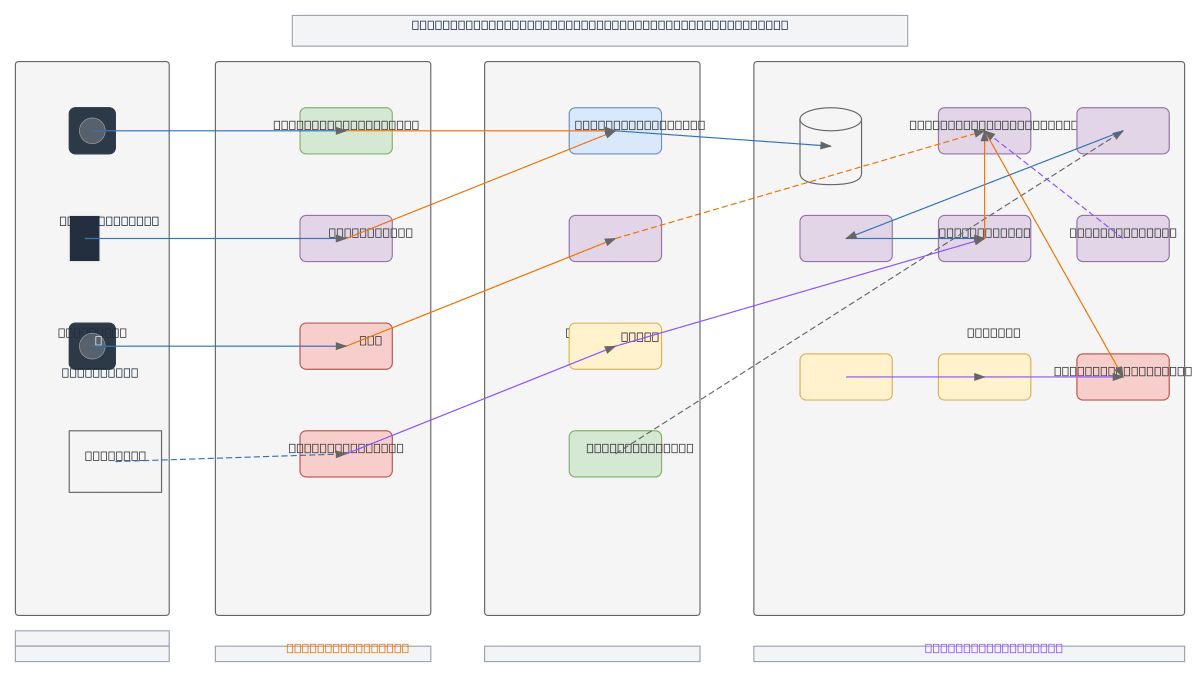
Enterprise chat application combining real-time messaging with retrieval-augmented generation (RAG) using Ollama or OpenAI models. User and IoT requests flow through a WAF-protected API Gateway into a FastAPI backend, which orchestrates message queuing, PostgreSQL + pgVector storage, and an embedding service feeding a vector database. The RAG pipeline retrieves contextual data and routes queries to AI models with safety guardrails, while monitoring and logging track system health across ingestion, processing, storage, and serving layers. This architecture demonstrates production-grade patterns for integrating LLMs into chat applications with enterprise security, caching, and observability. Fork and customize this diagram on Diagrams.so to adapt the RAG pipeline, swap AI model providers, or extend monitoring for your use case.
People also ask
How do you architect an enterprise chat application with retrieval-augmented generation and vector embeddings?
This diagram shows a production RAG chat system where user queries flow through a WAF-protected API Gateway to a FastAPI backend, which retrieves context from a vector database via an embedding service, then routes to Ollama or OpenAI models with safety guardrails. PostgreSQL with pgVector stores both relational data and embeddings, while message queuing and caching optimize throughput and latency
- Domain:
- Ml Pipeline
- Audience:
- ML engineers and data architects building enterprise RAG systems with real-time chat
Generated by Diagrams.so — AI architecture diagram generator with native Draw.io output. Fork this diagram, remix it, or download as .drawio, PNG, or SVG.