GCP Cost-Effective AI with GKE GPU Sharing
About This Architecture
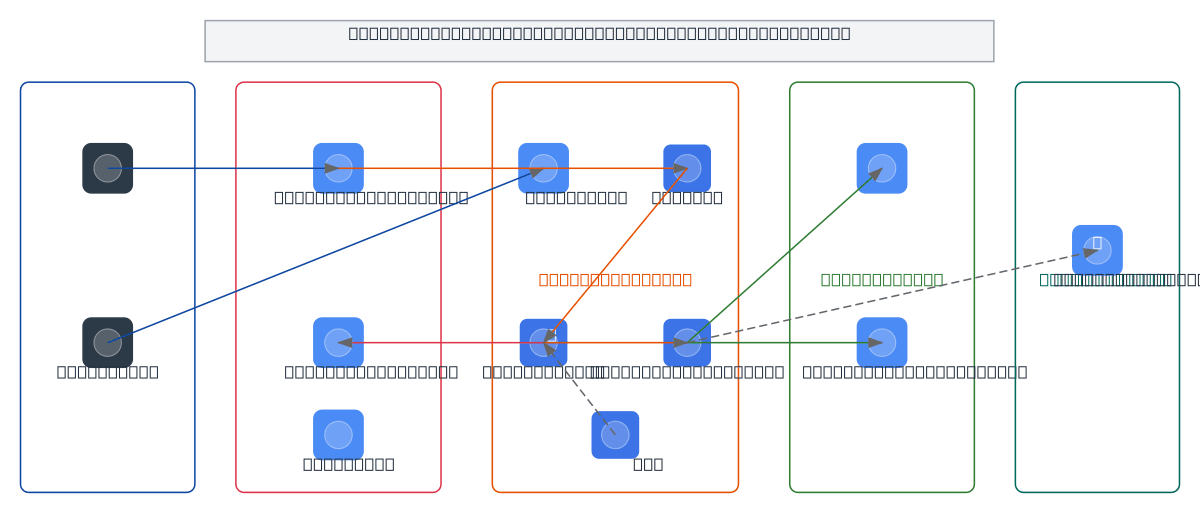
Cost-optimized AI inference architecture on GKE with GPU time-sharing and multi-tenancy using vCluster. Features Container Registry for model images, Cloud Storage for model artifacts, Memorystore for caching, and Cloud Monitoring for GPU utilization tracking. Fork this diagram on Diagrams.so to customize the GPU sharing strategy or add additional node pools for your inference workload. Source: https://cloud.google.com/blog/topics/developers-practitioners
Architecture prompt
Cost-optimized AI inference architecture on GKE with GPU time-sharing and multi-tenancy using vCluster. Features Container Registry for model images, Cloud Storage for model artifacts, Memorystore for caching, and Cloud Monitoring for GPU utilization tracking. Fork this diagram on Diagrams.so to customize the GPU sharing strategy or add additional node pools for your inference workload. Source: https://cloud.google.com/blog/topics/developers-practitioners
Generated by Diagrams.so — AI architecture diagram generator with native Draw.io output. Fork this diagram, remix it, or download as .drawio, PNG, or SVG.