AWS Real-Time AI Voice Assistant Architecture
About This Architecture
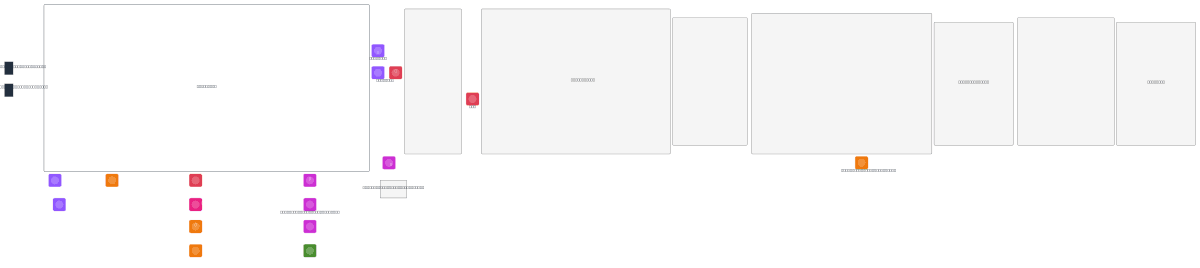
Multi-AZ real-time AI voice assistant on AWS combines WebRTC streaming via LiveKit, speech-to-text/text-to-speech via Cascade Agent, and LLM orchestration through Bedrock and Step Functions. Traffic flows from mobile and automotive clients through Route 53 and WAF to dual NLBs and ALBs across two availability zones, with streaming workloads on EKS and AI orchestration on Fargate. State is persisted across MongoDB, PostgreSQL, Milvus vector database, and ElastiCache with cross-AZ replication for high availability. This architecture demonstrates enterprise-grade patterns for low-latency conversational AI: stateless compute layers, distributed session management, vector search for context retrieval, and comprehensive observability via CloudWatch and CloudTrail. Fork and customize this diagram on Diagrams.so to adapt the topology for your voice assistant use case, adjust subnet sizing, or swap Bedrock for alternative LLMs.
People also ask
How do I architect a scalable real-time AI voice assistant on AWS with high availability and low latency?
This diagram shows a production-grade multi-AZ architecture using EKS for WebRTC streaming via LiveKit, Fargate for AI orchestration with Bedrock LLMs, and distributed databases (MongoDB, PostgreSQL, Milvus, ElastiCache) with cross-AZ replication. Route 53, WAF, and dual load balancers ensure resilience and security across availability zones.
- Domain:
- Cloud Aws
- Audience:
- AWS solutions architects designing real-time AI voice applications
Generated by Diagrams.so — AI architecture diagram generator with native Draw.io output. Fork this diagram, remix it, or download as .drawio, PNG, or SVG.