AWS End-to-End Data Engineering Pipeline
About This Architecture
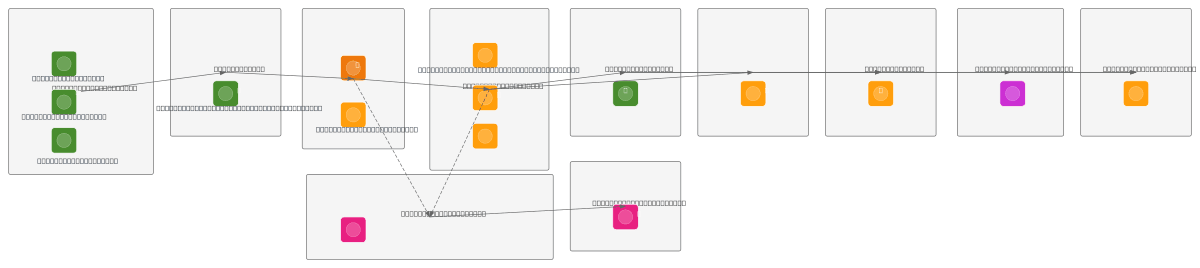
AWS end-to-end data engineering pipeline ingests CSV and JSON data from Orders, Customers, and Products sources into S3 Raw Bucket, triggered by Lambda on file arrival. AWS Glue ETL job cleans, deduplicates, and joins data, writing Parquet files to S3 Processed Bucket while populating Glue Data Catalog with schema and partitions. Amazon Athena queries partitioned data and feeds Amazon Redshift analytics warehouse and Amazon QuickSight dashboards for real-time visualization. CloudWatch and SNS provide comprehensive logging, monitoring, and alerting across the entire pipeline. This architecture demonstrates serverless scalability, cost optimization through S3 partitioning, and separation of concerns between ingestion, transformation, and analytics layers. Fork and customize this diagram on Diagrams.so to adapt data sources, transformation logic, or add additional query engines and visualization tools.
People also ask
How do I build a serverless end-to-end data pipeline on AWS that ingests, transforms, and visualizes data?
This diagram shows a complete serverless pipeline: raw CSV/JSON data lands in S3 Raw Bucket, Lambda triggers AWS Glue ETL to clean and deduplicate, Glue writes Parquet to S3 Processed Bucket and updates Glue Data Catalog, then Athena queries partitioned data feeding Redshift and QuickSight for analytics and dashboards. CloudWatch and SNS provide monitoring and alerting throughout.
- Domain:
- Data Engineering
- Audience:
- Data engineers building serverless ETL pipelines on AWS
Generated by Diagrams.so — AI architecture diagram generator with native Draw.io output. Fork this diagram, remix it, or download as .drawio, PNG, or SVG.