ASL Alphabet - Pipeline Donnees et Entrainement
About This Architecture
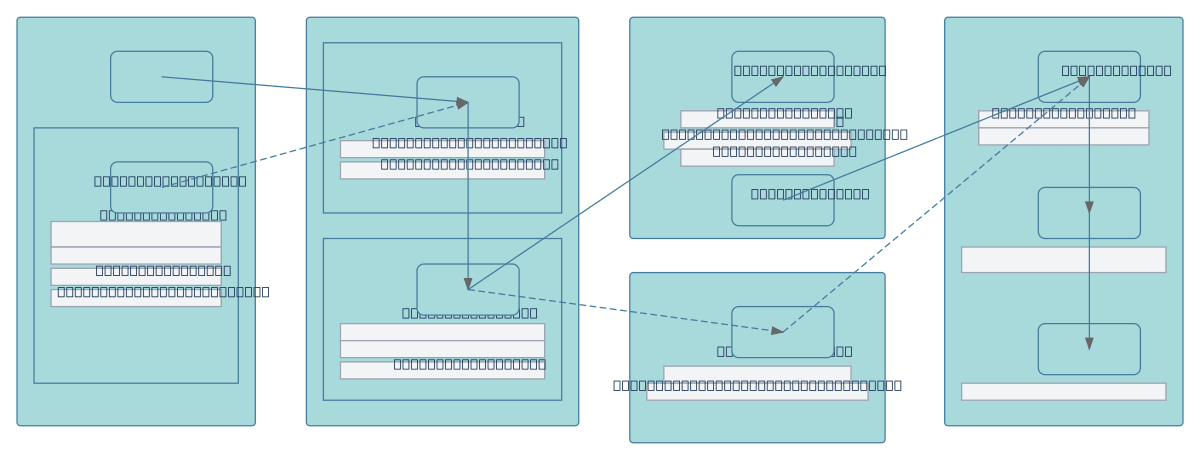
American Sign Language alphabet recognition pipeline ingests 87,000 balanced JPEG images from Kaggle across 29 classes, splits them 80/20 for training and validation with augmentation (rotation, zoom, brightness). A CNN model trains on 69,600 images, validates on 17,400, and deploys via an inference API with confidence thresholding and drift detection monitoring. This end-to-end workflow demonstrates best practices for balanced dataset preparation, augmentation strategy without horizontal flips, and production model governance. Fork and customize this diagram to adapt the pipeline for your own gesture recognition or computer vision classification tasks. The architecture emphasizes data quality and monitoring—critical for real-world ASL applications where model drift and confidence calibration directly impact user experience.
People also ask
How do you build a complete machine learning pipeline for sign language recognition from dataset to production inference?
This diagram shows a full ASL alphabet pipeline: ingest 87,000 balanced JPEG images, split 80/20 for training and validation, apply augmentation (rotation, zoom, brightness), train a CNN on 69,600 images, validate on 17,400, and deploy via an inference API with confidence filtering and drift detection monitoring.
- Domain:
- Ml Pipeline
- Audience:
- Machine learning engineers building computer vision pipelines for sign language recognition
Generated by Diagrams.so — AI architecture diagram generator with native Draw.io output. Fork this diagram, remix it, or download as .drawio, PNG, or SVG.